目前大模型的偏好对齐领域也是百家齐放,我们来记录一下市面上常见的对齐方法。
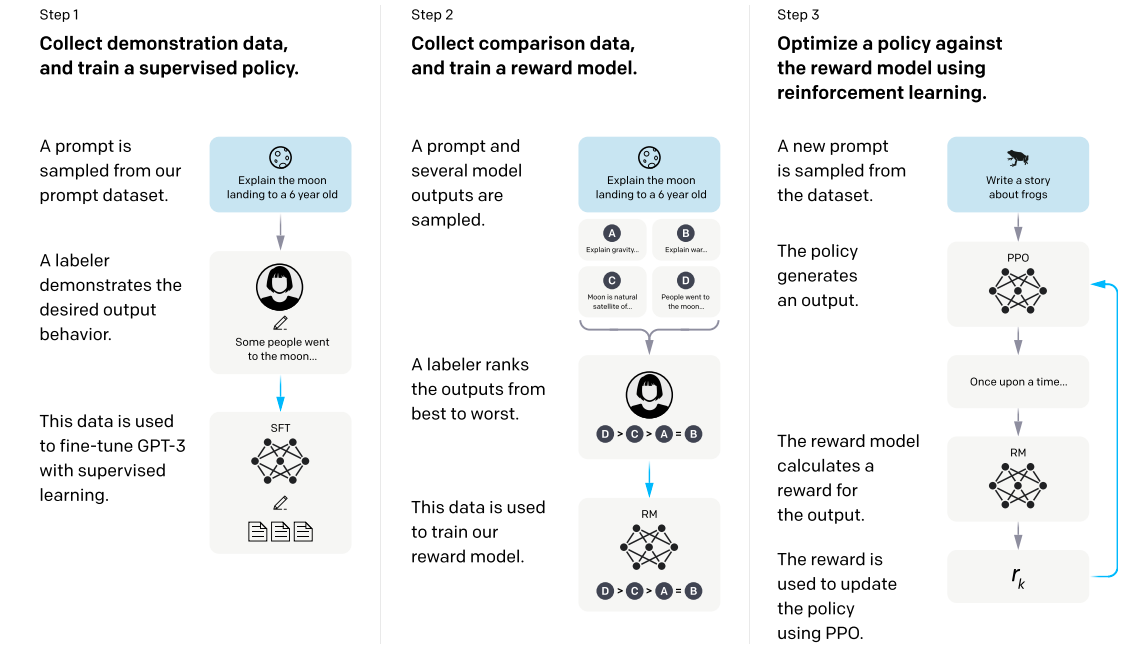
1 PPO
rlhf需要3个步骤,SFT / Reward / PPO
数据层面需要2个数据集,Reward数据集和PPO偏好数据集。
2 DPO
DPO相比PPO简单很多,DPO 将对齐公式重新定义为一个简单的损失函数,该函数可以直接在偏好数据集{(x,y_w,y_l)}上进行优化。所以不需要训练Reward模型,减少了Reward模型和数据集的准备,其次训练过程中也只需要2个模型,一个模型参与训练,另一个模型作为参考模型。
缺点:DPO容易过拟合。
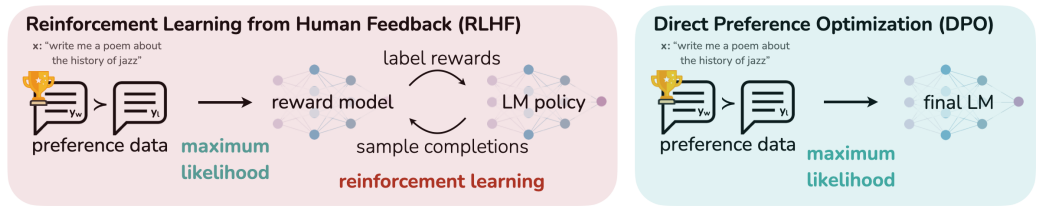
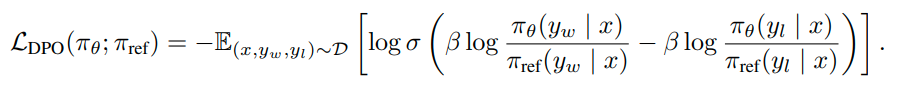
3 IPO
为了减轻DPO容易过拟合的问题,在DPO Loss的基础上增加了一个正则项,能够在不使用「提前停止」等技巧的情况下让模型收敛

4 KTO
虽然DPO的训练已经很简单,但是DPO需要的偏好数据集需要成对出现,“成对”这种形式依然需要高昂的标注成本。所以KTO只通过标记为“好”,“坏”的数据来定义损失函数,使数据更容易获取。
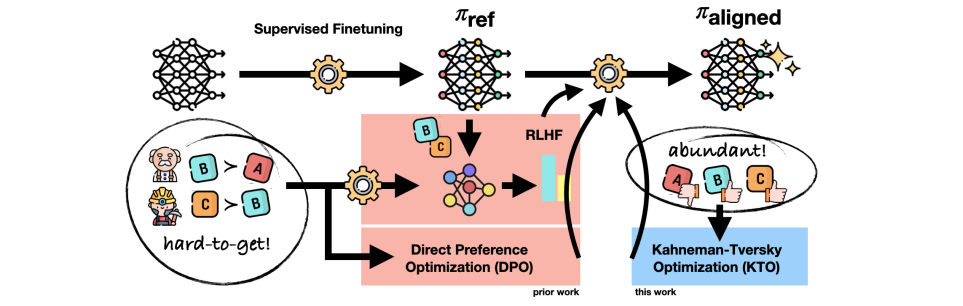
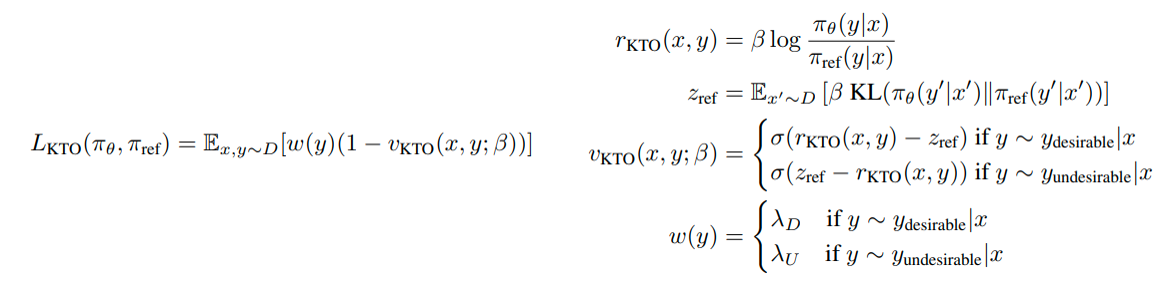
5 ORPO
ORPO直接进行SFT和对齐,具体而言ORPO的最大修改是修改Loss,同时优化SFT和对齐loss。
缺点:需要更大的偏好数据集和训练step。
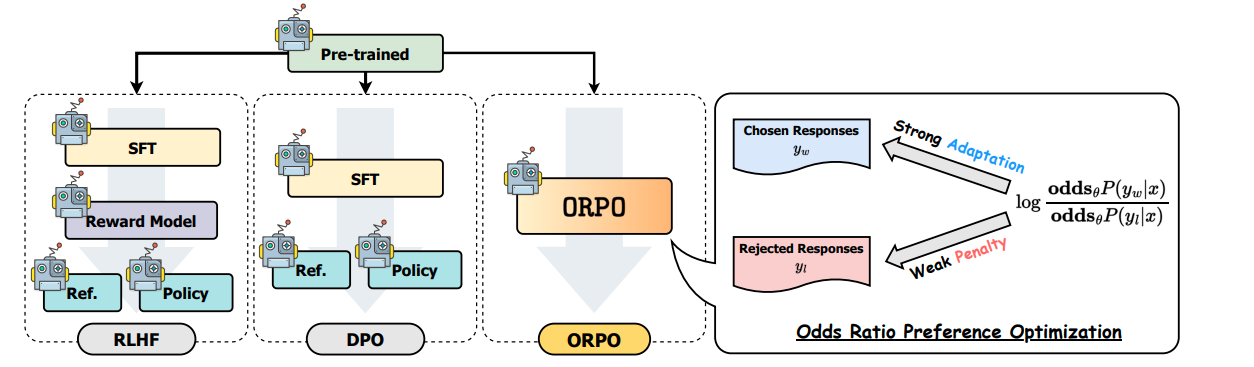
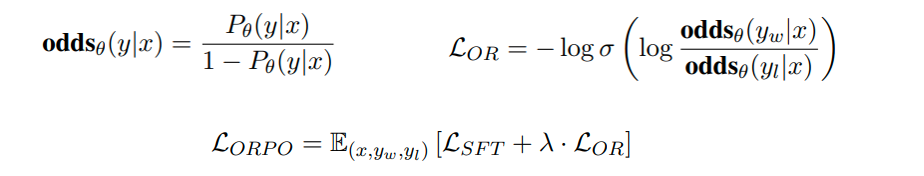
6 CPO
CPO Loss = DPO Loss – NLL Loss
7 参考文献
7.1 Blogs
PPO: [图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读 (qq.com)](https://mp.weixin.qq.com/s/E3zJ_456zo91QVRPgKNU_A)
DPO: [DPO: Direct Preference Optimization 论文解读及代码实践 (qq.com)](https://mp.weixin.qq.com/s/ckSRlXk530EmrErgEUPFOw)
DPO/IPO/KTO: [人类偏好优化算法哪家强?跟着高手一文学懂DPO、IPO和KTO (qq.com)](https://mp.weixin.qq.com/s/BcWqUN7SSi8q4Tsr7bFmTQ)
ORPO: [使用ORPO微调Llama 3 (qq.com)](https://mp.weixin.qq.com/s/7buvikDx3Fs0SvdpVRB4FQ)
ORPO: [ORPO偏好优化:性能和DPO一样好并且更简单的对齐方法 (qq.com)](
7.2 Papers
InstructGPT: [
PPO: [
DPO: [
IPO:
KTO:[
ORPO:[
CPO: [