自从huggingface的trl出现后,偏好对齐的训练越来越简单,到了只需要向封装的trainer中指定model和dataaset(甚至不需要tokenize),其他的trainer都会帮助实现。
DPO是一种近来替换PPO的高效简单的偏好对齐方法,由于其数据集构造简单,仅需要正负样本对即可开启训练,训练方式简单,只需要输入ref model(不像PPO需要ref model,reward model和critic model)。
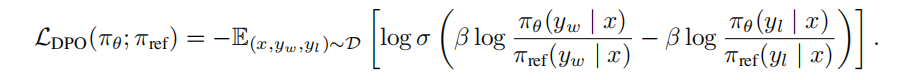
具体的原理篇请看:从PPO到DPO, KTO, ……
具体实验代码如下:
import os
os.environ["WANDB_DISABLED"] = "true"
import torch
import platform
from datasets import load_dataset
from trl import DPOTrainer
from transformers import (
AutoModelForCausalLM, AutoTokenizer,BitsAndBytesConfig, TrainingArguments
)
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
# 1 load model and tokenizer
# quantization_config = BitsAndBytesConfig(
# load_in_4bit=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.float16, bnb_4bit_use_double_quant=True
# )
model_config = dict(
load_in_8bit=True,
local_files_only=True,
# quantization_config=quantization_config,
device_map="auto", trust_remote_code=True, torch_dtype=torch.float16,
attn_implementation="flash_attention_2"
)
model_name = "qwen_0.5b" if platform.system().lower() == "linux" else r"qwen1.5"
model = AutoModelForCausalLM.from_pretrained(model_name, **model_config)
print(f"model load success!!!")
ref_model = AutoModelForCausalLM.from_pretrained(model_name, **model_config)
ref_model.config.use_cache = False
print(f"ref model load success!!!")
# model = prepare_model_for_kbit_training(model, use_gradient_checkpointing=True)
model.config.use_cache = False
lora_config = LoraConfig(r=8, lora_alpha=16, lora_dropout=0.3,
target_modules=["q_proj", "v_proj", "k_proj", "o_proj"], task_type="CAUSAL_LM", bias="none")
model = get_peft_model(model, peft_config=lora_config)
model.print_trainable_parameters()
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.add_special_tokens({"bos_token": tokenizer.eos_token})
tokenizer.bos_token_id = tokenizer.eos_token_id
tokenizer.padding_side = "left"
print(f"tokenizer load success!!!")
# 2 load dataset
def get_prompt(row):
prompt = "Human: " + row["prompt"] + "Assistant: \n"
return prompt
def generate_token(row):
prompt = get_prompt(row)
return {
"prompt": prompt,
"chosen": row["chosen"],
"rejected": row["rejected"]
}
dataset_name = "./dataset/toxic-dpo.parquet"
dataset = load_dataset("parquet", data_files=dataset_name, split="train")
original_columns = dataset.column_names
train_val_dataset = dataset.train_test_split(test_size=0.01, shuffle=True, seed=42)
train_dataset = train_val_dataset["train"].shuffle().map(generate_token, remove_columns=original_columns)
val_dataset = train_val_dataset["test"].shuffle().map(generate_token, remove_columns=original_columns)
# 3 trainer
dpo_config = TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
warmup_steps=50,
num_train_epochs=1,
learning_rate=5e-5,
fp16=True,
logging_steps=1,
optim="adamw_torch",
evaluation_strategy="steps",
eval_steps=6,
output_dir="./cache",
ddp_find_unused_parameters=False,
dataloader_drop_last=False,
gradient_checkpointing=True
)
trainer = DPOTrainer(
model=model,
ref_model=ref_model,
beta=0.1,
train_dataset=train_dataset,
eval_dataset=val_dataset,
tokenizer=tokenizer,
max_length=512,
max_prompt_length=128,
args=dpo_config
)
trainer.train()
trainer.save_model("./output")