深度学习中相信大家肯定都对dataset,sampler,collator,dataloader这些名词并不陌生,但是可能有很大一部分从业人员可能对数据加载过程的原理不是特别了解,那么今天我们来探析一下这些模块之间的关系。
- 1 dataset:首先dataset是建立数据集的索引形式,建立后可以通过dataset[item]访问数据。
- 2 collator:深度学习需要的数据是批次化的,collator的作用就是将来自dataset的多个data变成批次形式.
- 3 dataloader:由于直接读取全部的数据内存无法承受住,故目前深度学习的主流是使用生成器,即在使用数据的时候才返回数据。dataloader实际上就是一个生成器,dataloader利用sampler获取需要返回数据的indice,然后将对应的dataset的索引给collator进行处理成batch数据,最后返回给用户。
1 dataset
此处我们使用模拟数据来建立一个dataset,让大家体验一下dataset的作用和形式。
- 1 使用numpy创建一个(1000, 64)维度的特征。
- 2 自定义一个MyDataset(继承自Dataset),需要实现__init__(), __len__(), __getitem__()三个魔法方法。
- 3 魔法方法的具体实现
- 3.1 __init__() 一般数据在此处定义
- 3.2__getitem__()方法,该方法为具体获取索引数据的方法。
- 3.3 __len__(),获取data的长度
import torch
from torch.utils.data import Dataset, DataLoader
class MyDataset(Dataset):
def __init__(self):
super().__init__()
self.data_list = np.random.randn(1000, 64)
def __getitem__(self, index):
return {"data": self.data_list[index]}
def __len__(self):
return len(self.data_list)
if __name__ == '__main__':
dataset = MyDataset()
print(dataset[0])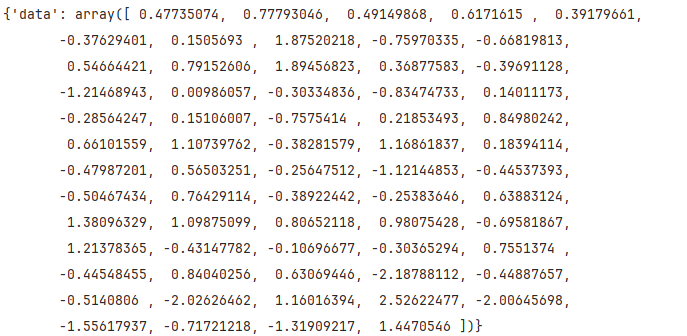
2 collator
import torch
import numpy as np
from torch.utils.data import Dataset, DataLoader
class MyDataset(Dataset):
def __init__(self):
super().__init__()
self.data_list = np.random.randn(1000, 64)
def __getitem__(self, index):
return {"data": self.data_list[index]}
def __len__(self):
return len(self.data_list)
class MyCollator(object):
def __init__(self):
super().__init__()
def __call__(self, batch):
batch_return = []
for x in batch:
batch_return.append(x["data"])
batch_return = torch.tensor(np.array(batch_return))
return batch_return
if __name__ == '__main__':
dataset = MyDataset()
collator = MyCollator()
print(collator([dataset[0], dataset[1]]))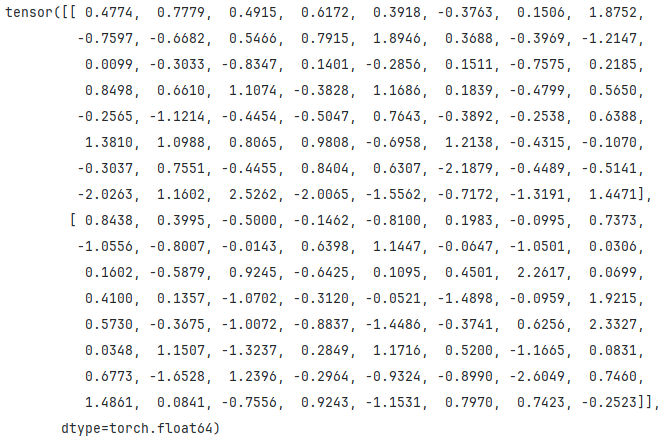
3 dataloader
if __name__ == '__main__':
dataset = MyDataset()
collator = MyCollator()
dataloader = DataLoader(dataset, collate_fn=collator, batch_size=2, shuffle=True)
for i, batch in enumerate(dataloader):
if i == 10:
print(batch)3.1 batch_size和shuffle=True
dataloader中可以设置batch_size决定了返回数据的batch,同时我们看到dataloader中可以设置shuffle=True,这是怎么实现的呢?
答案:由Sampler控制,这些都可以从源码中找到答案。
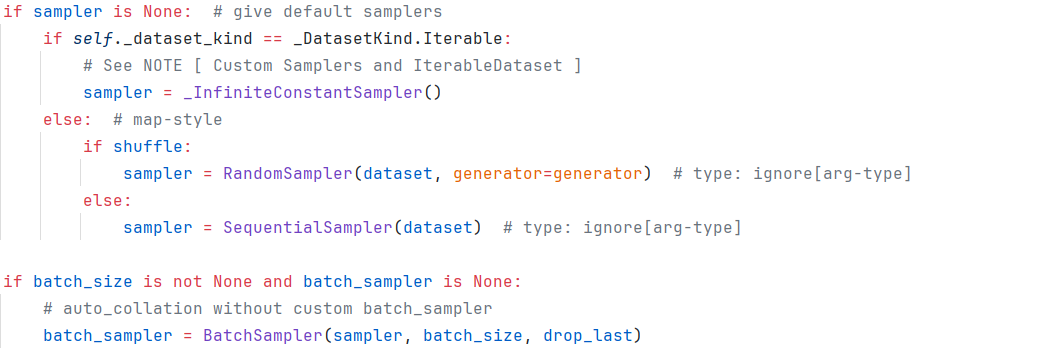
- 1 当shuffle=True时,使用RandomSampler对索引进行打乱返回,否则返回SequentialSamper将索引顺序返回。
- 2 当batch_size不为None时,在RandomSampler或者SequentialSampler的基础上使用BatchSampler。
3.1.1 RandomSampler
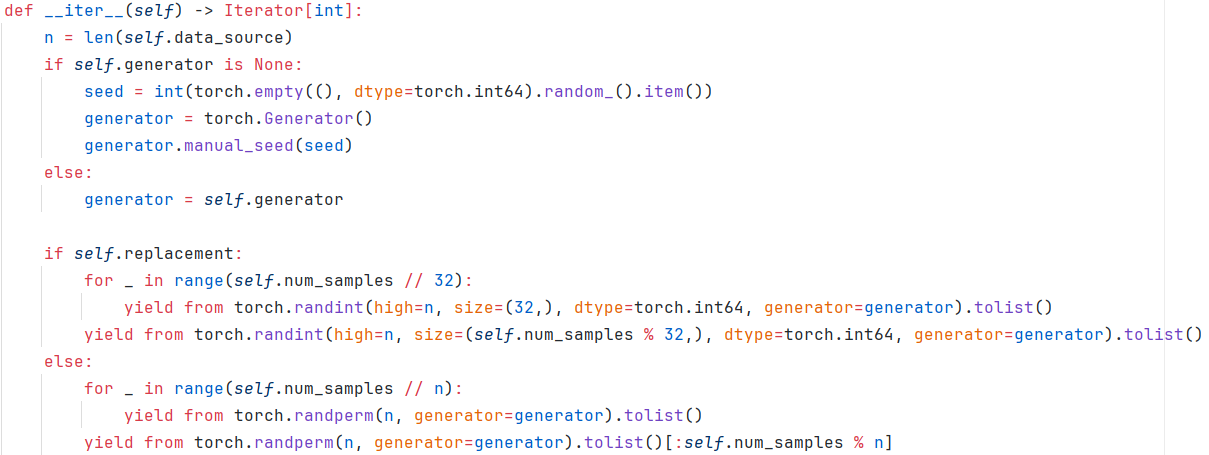
self.generator默认为None,self.replacement默认为False。故默认的RandomSampler会创建一个生成器,然后self.num_samples和n都是Dataset的长度,故最后返回的为对索引的打乱索引。
3.1.2 SequentialSampler
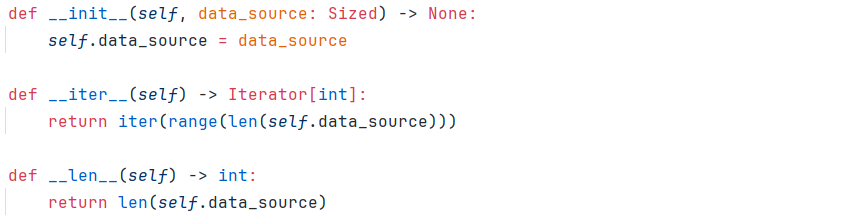
3.1.3 BatchSampler

上述为BatchSampler的核心代码:
- 1 先创建一个长度为batch_size大小的[0]数组batch;
- 2 遍历batch_size个大小的sampler中的索引填充到batch数组中;
- 3 当batch_size等于batch数组的长度时,返回batch索引数据,同时将batch重新设置为全0数组,同时设置idx_in_batch长度为0;
3.2 num_workers = n

以上为dataloader的核心代码,故dataloader需要使用self._get_iterator()获取迭代器。

当num_workers=0时使用单进程迭代器,num_workers>1时使用多进程迭代器。
3.2.1 _SingleProcessDataLoaderIter

index是从sampler从获取,data从fetcher中获取,当pin_momory=True时,数据在内存中常驻。
fetcher使用collator对dataset进行处理,处理后将数据返回。

故数据的流动如下:()中为数据,非()为模块
(n) -> sampler -> (index) -> fetcher -> dataset -> collator -> data
3.2.2. _MultiProcessingDataLoaderIter
上述过程使用多进程处理,将batch内的数据分为N块,每块数据由一个子进程进行处理,处理完成之后拼接回原数组。