大模型的位置编码经历了绝对位置编码(sin/cos) -> 相对位置编码(RoPE, ABiLi)的进化历程。
之前的绝对位置编码和相对位置编码都是基于token,无法关注到token的上下文的位置关系。
MeTa最近提出了CoPE用以关注token上下文之间的位置关系,使大模型可以关注某个token和word, noun, sentence之间的位置关系,最终可以解决例如count, selective copying 和Flip-Flop任务。
1 CoPE原理
CoPE不再通过一个相对整数位置来表示相对位置,而是通过qk计算的门控累加形式来获取相对位置。
- 1 门值计算:CoPE首先根据上下文计算门值(gates)。这是通过使用当前标记的查询向量(query vector)和先前标记的键向量(key vectors)计算点积,然后应用sigmoid函数来实现的。门值决定了哪些标记在计算位置时应被考虑。
- 2 累积求和:接着,CoPE使用这些门值来确定每个标记相对于当前标记的位置。这是通过在当前标记和目标标记之间的门值上进行累积求和来实现的。
- 3 位置插值:与基于标记的位置编码不同,CoPE的位置值可以是小数,因此不能直接分配嵌入向量。CoPE通过对最接近的整数值的嵌入向量进行插值来计算位置嵌入。
- 4 注意力计算:最后,CoPE使用这些位置嵌入来调整注意力权重,使得查询向量可以在注意力操作中使用它们。

这里来看一个极端的例子,我们直接关注到CoPE。
- 1 门值计算:Gates
- 1.1 Gates中A, rabb, -it, came都是0,这里是指以came作为q,A, rabb, -it, came作为k,计算得到的sigmoid(q^Tk)的值都为0.
- 1.2 Gates中的.为1,即came的q与.的k计算的门值为1
- 2 累计求和: Position
- 2.1 通过累计求和这里可以看出,came这个token与 She tried reading .整个句子之间的相对距离为1,这意味着came产生了与句子之间的相对位置关系。
- 2.2 came这个token与 Alice was tired .整个句子之间的相对距离为2.
- 3 位置插值
- 3.1 由于上图的例子比较极端,将sigmoid取0或者1,实际上sigmoid的值是0~1的小数,故对于Embedding层无法取得嵌入值,所以选择插值方法,将小数变成最相近的整数。
- 3.2 插值办法选择了上下插值方法,分别针对上下插值的整数取得权值,分别为上下插值整数embedding做权值求和。
- 4 注意力计算:Attention
- 4.1 相对位置嵌入与k的嵌入相加,参与q^Tk的attention的计算。
2 CoPE公式
这里将CoPE的原理转化为专业的公式。
2.1 门值计算

2.2 累计求和

2.3 位置插值

2.4 注意力计算
原版算法:
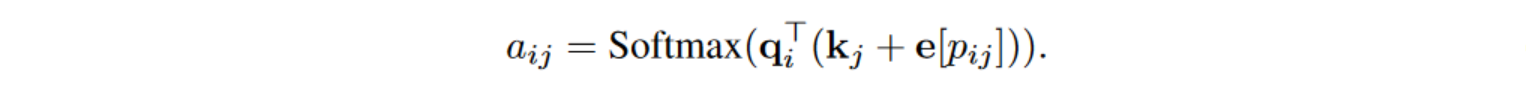
优化算法:
可以提前将q_i与k_j的相对位置的嵌入全部计算好,计算时索引即可。

3 CoPE Task
3.1 Flip-Flop Task
Flip-Flop任务用于检验长序列输入的推理能力的鲁棒性。
首先介绍一下Flip-Flop任务,我们给出一个由{w, r, i}交替的指令序列(write, read, ignore),每一个字母之后都会跟着1或者0,保证由w开头,r结束。
这些字母的定义如下:
- w代表写入跟在w之后的数字作为记忆。
- i忽略信息。
- r代表需要找回最后一个记忆。
简要概括:
- 1 i以及i之后的数字可以忽略
- 2 只需要查看最后一个r的前一位的w后的数字即为最后的答案。
简要举例:“w0i1r0w1i0i1i1r” -> r前一个w的数字为1,故答案为1.
3.2 Selective copying
由Gu和Dao提出的选择性复制任务需要上下文感知的推理来进行选择性记忆。在这个任务中,模型被给予一系列的符号,并被要求复制所有符号,除了指定的空白符号。例如,当输入是DBBCFBFBE,其中B是空白符号时,模型应输出DCFFE。
在实验中,词汇表大小设置为16,输出序列长度(非空白符号的数量)设置为256,并改变空白符号的数量。训练和分布内测试数据有256个空白符号,而密集和稀疏的分布外测试数据分别有128个和512个空白符号。

3.3 Counting

3.evaluate
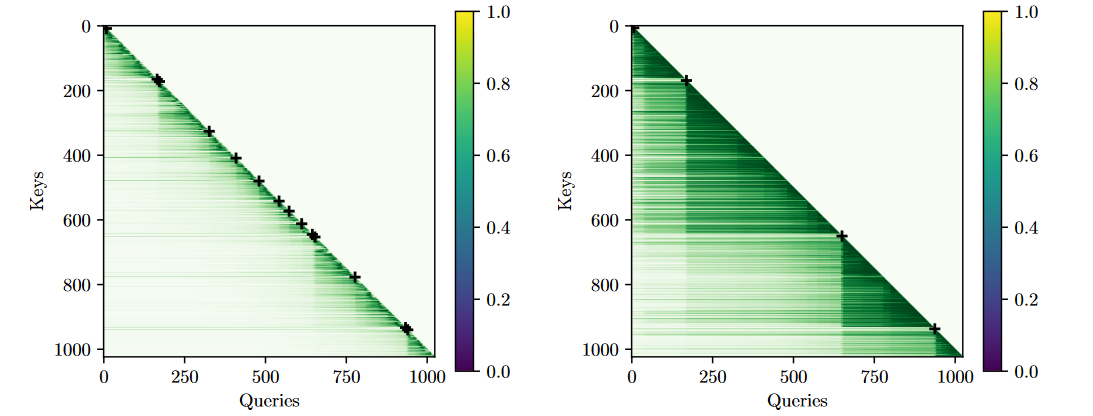
在Wikitext-103上可视化了Attention,从Queries向左看,我们发现,Queries的注意力集中在某一段,而这些段刚好是真实存在的。这意味着CoPE可以为某段分配差不多的相对位置和注意力。