Mamba作为时序状态空间类模型的扛把子之作,一开始就是打着取代Transformer的架构的目的而来的,我们来看一下到底Mamba的魅力在哪里,又是如何能取代Transformer架构呢?
1 时序状态空间模型SSM
状态空间模型SSM其实来着控制领域,控制领域通常将一个系统建模成线性时不变系统,即如下图所示:
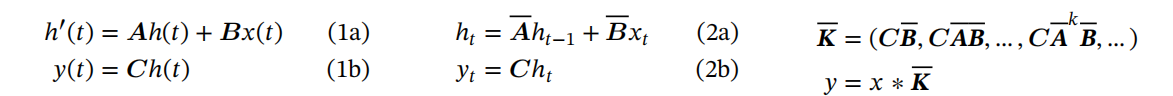
![]()
对(1a)进行求导拆分和离散化(零阶保持器)就可以变成(2a)所示的迭代式。
1.1 卷积表达式(训练)
从上述公式可以看到,迭代多次之后可以根据矩阵乘法定义抽象出K,则y=x*K。
这表示SSM在训练的时候可以像卷积一样进行并行化。
1.2 递归表达式(推理)
推理时即为原本的公式,故推理只需要经过一次迭代即可。
1.3 优缺点
- 优点:训练CNN-like并行,推理RNN-like迭代。
- 缺点:由于是线性时不变系统,模型的参数和表达能力受限,模型性能和泛化性严重不足。
2 Mamba
Mamba为了解决经典的SSM由于LTI系统建模导致的表达能力和泛化性差的问题,引入非线性时变的建模方式。
2.1 Mamba block
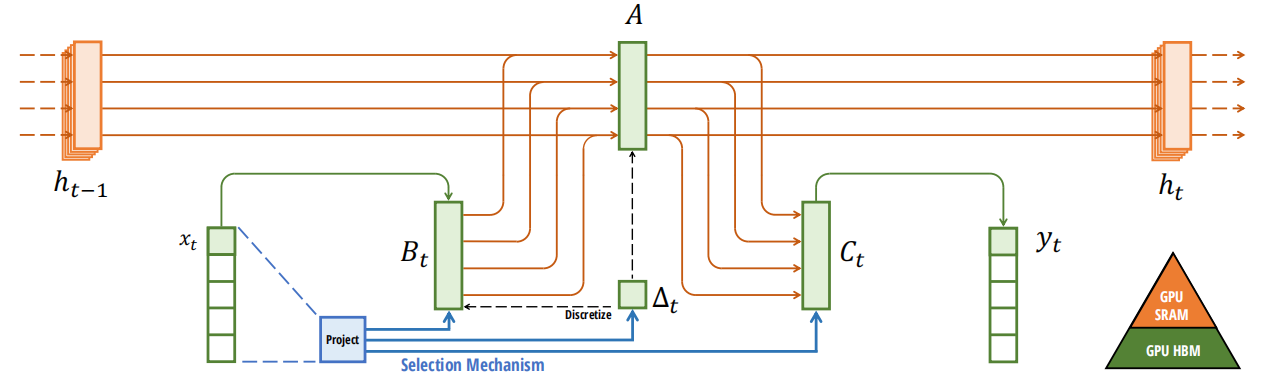

2.2 Mamba design
2.1小节已经展示了Mamba的model和公式,那么这里我们来具体的探讨Mamba如何将非线性和时变引入SSM,同时又是为何这么设计。
2.2.1 引入时变
首先,为了增强Mamba模型的性能使模型架构中的A,B,C都随着模型的输入而发生改变,故Mamba将B,delta和C是由输入x通过线性变化得到(B,C,delta共享同一个权重),这样B,C都引入了时变,同时delta可以作用于A使其也引入时变。
2.2.2 引入非线性
由于delta的公式存在指数函数,故引入了非线性。
在离散化的过程中delta会作用于A和B,故将非线性引入了A和B。
2.2.3 设计思想
这里我们会存在一个特别大的疑问?为什么这里Bt和Ct是直接从输入x经过线性映射引入的时变,A却通过delta引入,为什么不保持对称性,A也通过x经过线性映射引入呢?
答案是保持稳定性和泛化性!
我们可以参考LSTM的设计,LSTM流通的记忆分为两个部分:细胞状态C(全局记忆),隐藏状态h(局部记忆)。
- 1 细胞状态C_t=i_t* z_t+ f_t * C_t-1,C_t需要输入门和遗忘门两个的影响,这导致Ct的变化幅度是受限的,Ct基本上可以看做会保留历史记忆和输入信息,这种记忆我们看成是长期记忆,因为Ct更新幅度小,而且同时保留历史记忆和当前的输入信息,这使得训练很稳定。
- 2 隐藏状态h_t = o_t * h_t-1,h_t的状态只由输出门o_t控制,导致变化波动大,一般我们看成是局部信息。
故通过LSTM的设计我们可以看出,类比LSTM,Mamba中的h可以看成长期记忆,x看成局部信息,如果这里的A也设置成通过x经过线性映射引入非线性,这导致A的变化非常大,历史记忆波动非常明显,这明显会让训练不稳定,性能和泛化波动。故从大局观着想,我们应该让历史记忆更新缓和一点,局部信息更新可以激进一点。
2.3 Mamba Model

3 LSTM vs Mamba
上述我们讨论了很多LSTM和Mamba,大家会发现LSTM和Mamba的设计其实非常类似,都是使用门控机制来控制模型内部信息的流动,同时为了保持模型的稳定性,设计了长期记忆和短期记忆,同时迭代公式也非常类似。

相同点:
- 1 LSTM和Mamba引入时变的方式也一样,利用门控机制
- 2 LSTM和Mamba的迭代更新公式非常类似,其实都可以看成具备输入门,遗忘门和输出门,而且门的位置都一样。
不同点:
- 1 LSTM内部使用细胞状态(全局)和隐藏状态(局部),Mamba只有隐藏状态(全局)和输入(局部)。
- 2 LSTM的门是输入通过映射和激活函数(sigmoid)而来,Mamba的门中输入门和遗忘门都经过了映射和离散化而来。
4 思考和总结
个人认为Mamba实际上的设计和LSTM如出一辙,LSTM会遇到的问题,Mamba大概率也会遇到(记忆容量不足,长序列建模能力差,无法实现真正的并行)。
但是具体为什么Mamba的长序列建模能力比LSTM强呢,本人还没有具体的想法,可能是SSM这种需要离散化的建模方式受到梯度消失或者梯度爆炸的影响小。