上文我们已经详细介绍了LSTM:LSTM详解
1 LSTM回顾
所谓的门控机制,实际上就是一种时序上的注意力机制,核心思想都是选择性控制信息流动,更好的处理时序数据或者序列信息。
门控机制通过固定的结构和参数来控制信息流,而相比Transformer使用动态的计算权重来控制信息流,门控机制可以认为是一种约束版的注意力机制。
那么问题来了,既然LSTM看起来很好,为什么在长序列建模中没有大获全胜呢?
LSTM的局限性:
- 1 处理长序列效率低
- 2 记忆容量有限
- 3 不能并行处理数据
公式如下:
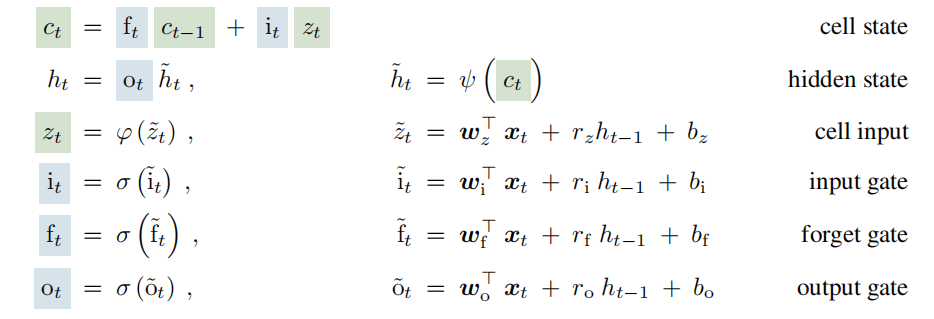
2 sLSTM
针对LSTM处理长序列效率低的局限性,sLSTM进行了注意力机制的改动:
- 1 输入门和遗忘门的sigmoid函数变成了指数函数。
- 2 引入了归一化状态nt。
- 3 引入了额外状态mt来稳定门控。
公式如下:

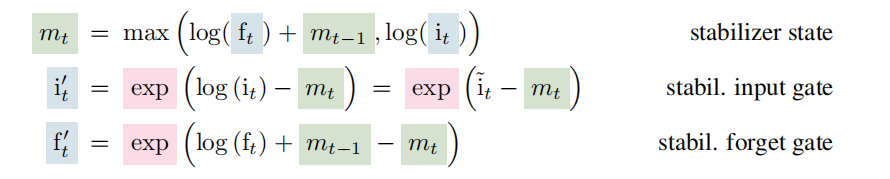
从公式可以看出,sLSTM主要的精力在于修改隐藏状态ht:
- 1 为了使输入门和遗忘门更敏感,使用了指数激活函数。
- 2 为了稳定输入门和遗忘门的敏感问题,引入了m_t和n_t来控制ht
3 mLSTM
sLSTM通过修改门控机制加强了长序列处理的效率问题,此处为了处理LSTM的记忆容量有限的问题和并行化问题,将记忆单元c从一个标量变成了一个矩阵C。
公式如下:

从公式可以看出,mLSTM使为了解决记忆容量的问题,引入了矩阵C。
mLSTM为了解决并行化问题,引入qkv,将原来的候选记忆的实现变成了qkv的实现来实现并行。
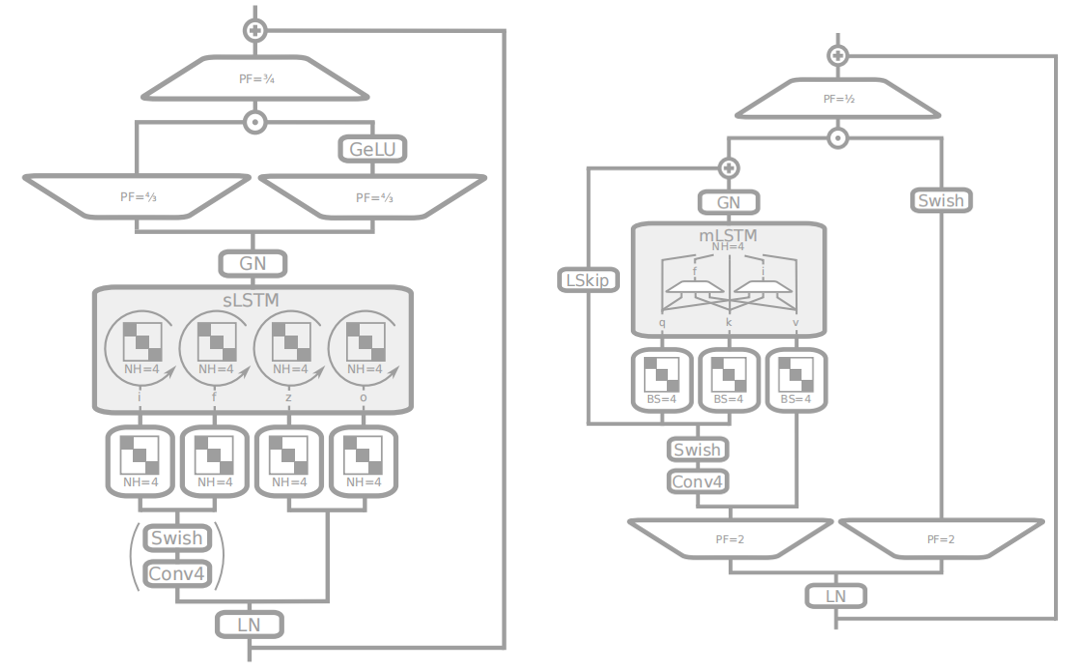
4 xLSTM
xLSTM的改进在于模型堆叠。
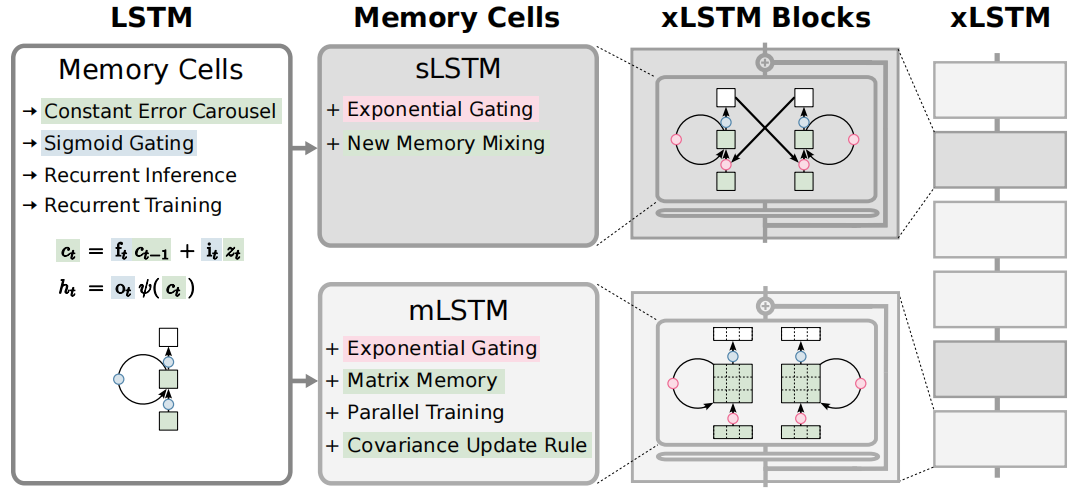
具体的框架如下: