目前LoRA已经成为主流的微调方法,目前的主流微调方法分类如下:
Prompt Learning: Prompt Tuning ; p-tuning; p-tuning v2; prefix-tuning
稀疏微调: 引入一个初始步骤来确定关键参数。这个过程利用各种度量,如Fisher信息或L0正则化,来确定哪些参数是必要的。然后在后续的训练阶段特别针对这些参数进行训练。
1 LoRA Adapter
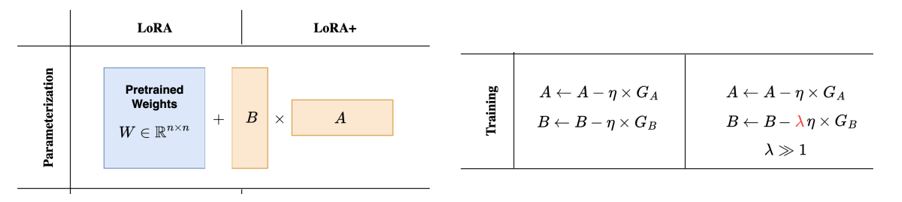
1.1 LoRA
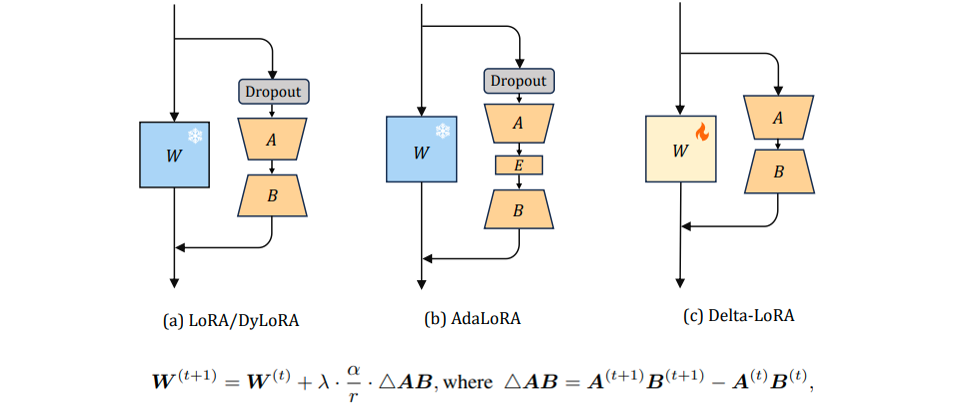
A被初始化为均值为0的随机值(高斯初始化),B被初始化为0矩阵。

1.2 LoRA+
A、B需要不同的学习率(因为A为随机均匀初始化,B设置为0矩阵,所以B需要更多更新才能更上A),故给B矩阵设置更大的学习率可以加速收敛。参数可以设置成16.
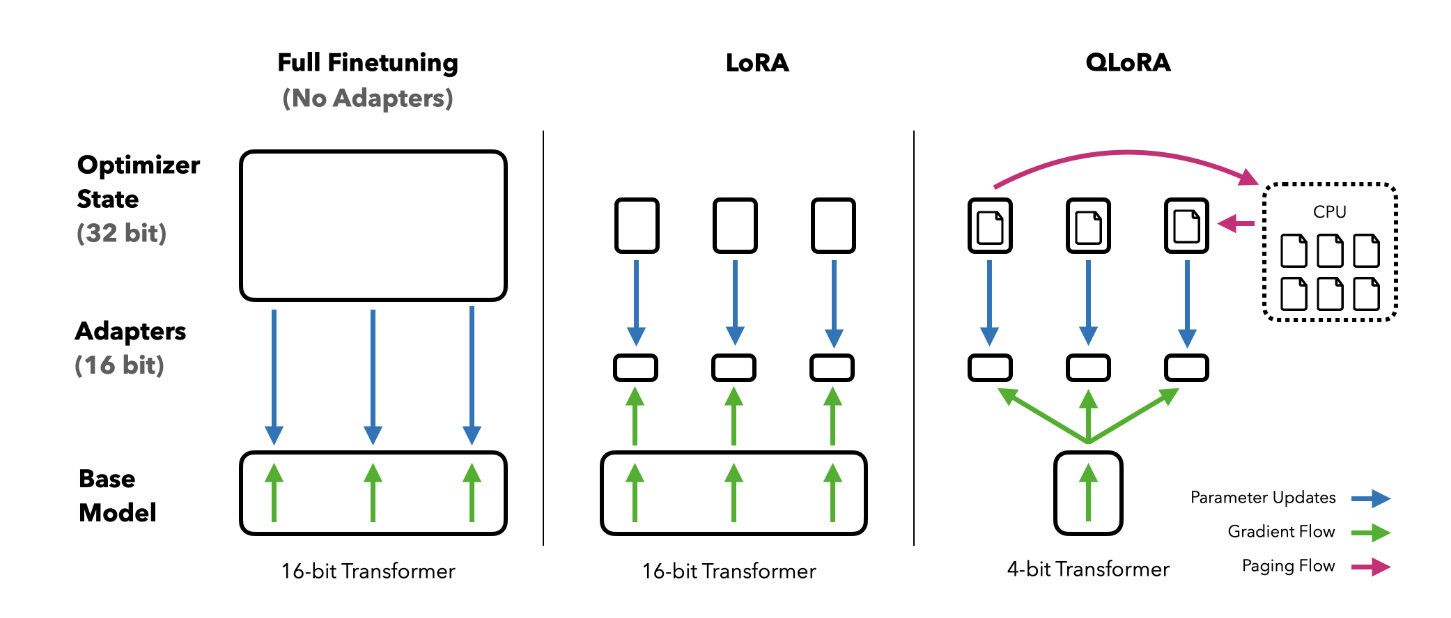
1.3 QLoRA
分位数量化(NF4数据格式)+双重量化+内存尖峰优化器 + LoRA
1.4 DoRA
DoRA将incredent matrix分解为幅值向量和方向矩阵,然后保持幅值向量正常更新,方向矩阵使用LoRA进行更新。
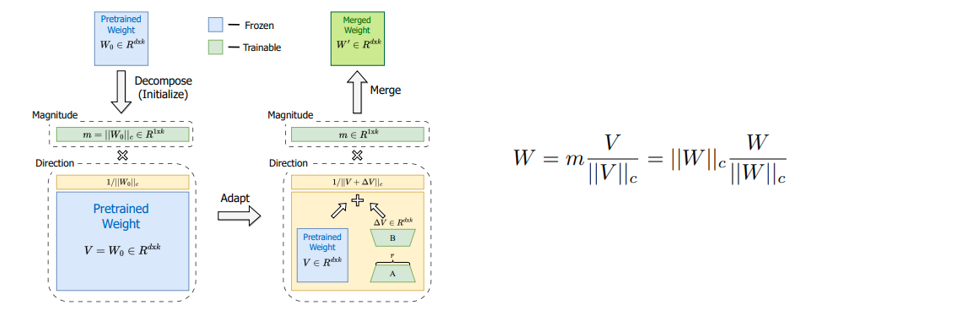
FT的幅值更新和方向矩阵更新为负相关(节点都处于一个大一个小的地方)。LoRA为正相关(节点处于两个都大的地方),DoRA也是负相关。

个人思考:非常新颖的思考,从权重归一化的角度出发探索FT和LoRA微调模式的区别,引出DoRA,最后发现DoRA的微调模式与FT相似,而且收敛快。
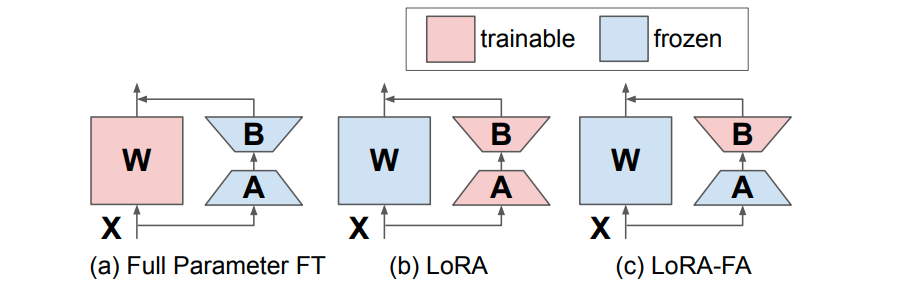
1.5 LoRA-FA
将A矩阵也冻结(随机初始化),只微调B矩阵。
1.6 VeRA
A、B矩阵都冻结(全部的矩阵共享同样的随机初始化参数),但是引入新的b、d对角矩阵进行微调。

1.7 LoRA-Delta
在LoRA的基础上对预训练矩阵W进行更新,使用AB矩阵的梯度来更新W。
1.8 LoRA-Drop
LoRA-drop引入了一种算法来决定哪些层由LoRA微调,哪些层不需要。
LoRA-drop包括两个步骤。在第一步中对数据的一个子集进行采样,训练LoRA进行几次迭代。然后将每个LoRA适配器的重要性计算为B*A*x,其中A和B是LoRA矩阵,x是输入。这是添加到冻结层输出中的LoRA的输出。如果这个输出很大,说明它会更剧烈地改变行为。如果它很小,这表明LoRA对冻结层的影响很小可以忽略。
选择最重要的LoRA层也有有不同的方法:可以汇总重要性值,直到达到一个阈值(这是由一个超参数控制的),或者只取最重要的n个固定n的LoRA层。无论使用哪种方法,还都需要在整个数据集上进行完整的训练(因为前面的步骤中使用了一个数据子集),其他层固定为一组共享参数,在训练期间不会再更改。
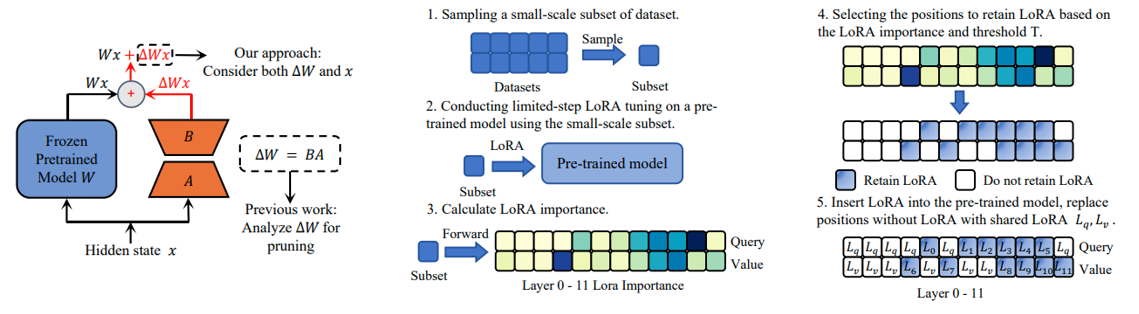
1.9 AdaLoRA
与上述LoRA-Drop不同,每个层都会进行更新,只是r不一样。
给重要的layer给予更多的参数(秩r大),给不重要的layer给与更少的参数(秩r小)。
量化每一个奇异值对模型性能的影响,进行排序,高被保留,低置为0.
奇异值和奇异特征向量都是估计出来的,初始将奇异值向量设置为0,奇异特征向量设置为正交,同时使用loss约束其在训练过程中也正交。
拥有全局控制器,控制总体的r保持不变。

1.10 LISA
LoRA 的分层权重范数具有罕见的偏态分布,底层和顶层在更新过程中占据了大部分权重,而其他自注意力层只占很小一部分,这意味着不同层次在更新时的重要性各不相同。
本文提出了分层重要性采样 Adam (LISA) 算法,即有选择性的更新必要的 LLM 层并保持其他层不变。

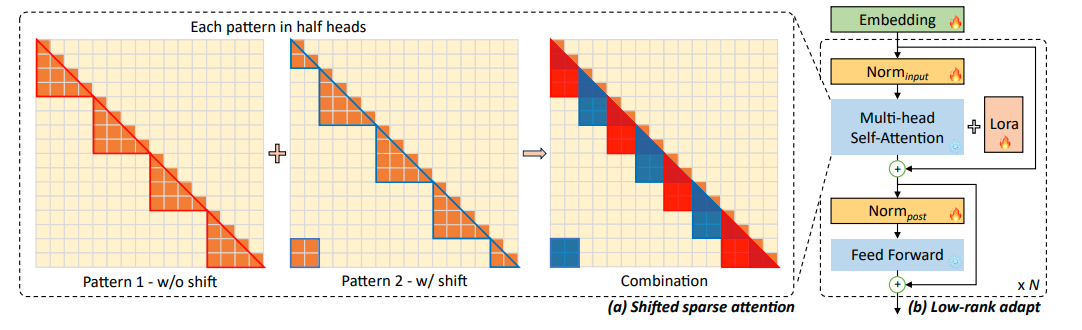
1.11 LongLoRA
Shifted sparse attention + all LoRA(self-attention + Embedding + Norm)
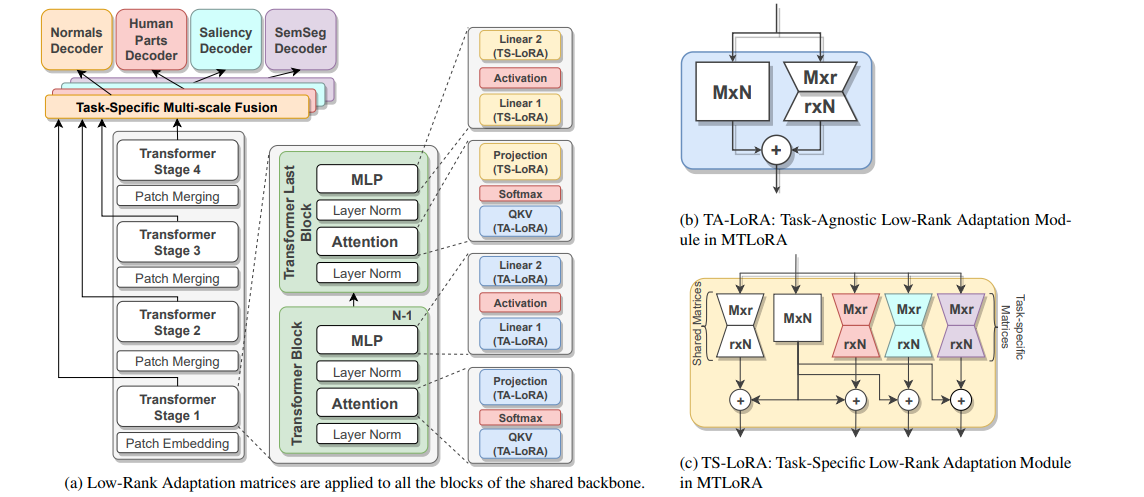
1.12 MTLoRA
MTLoRA框架通过结合任务无关(Task-Agnostic)和任务特定(Task-Specific)的低秩适应模块,有效地解决了在多任务学习(MTL)中的参数高效微调问题。
任务无关的低秩适应模块(TA-LoRA)旨在捕获多个下游任务之间的共享特征,而任务特定的低秩适应模块(TS-LoRA)则专注于学习每个任务的独特特征。这种策略不仅提高了模型在各个任务上的准确性,而且还显著减少了训练参数的数量,实现了准确性和效率的最优权衡。
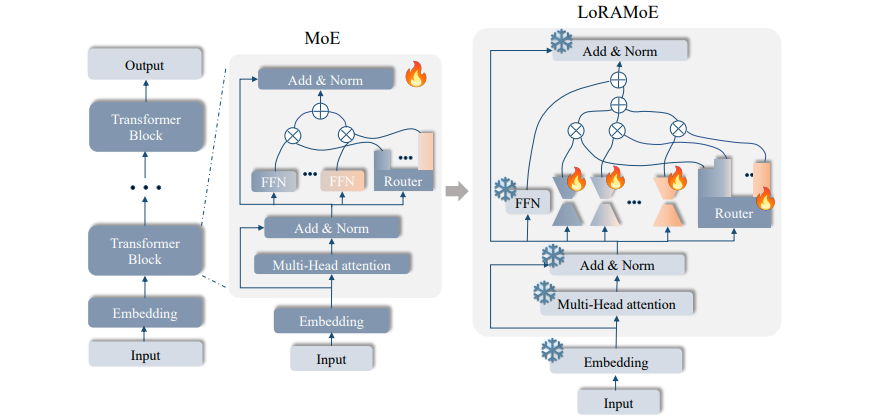
1.13 LoRAMoE
很直觉,LoRA+MoE思想的扩展。
2 Prompt Learning
- 1 Prompt-Tuning和P-TuningV2不做重参数化,Prefix-Tuning使用两层MLP和P-Tuning使用LSTM和一层MLP做参数化。
- 2 Prompt-Tuning和P-Tuning只在输入层加Virtual Prompt,Prefix-Tuning和P-TuningV2在每一层都加上Vitrtual Prompt。
2.1 Prompt-Tuning
在输入层的Prompt的前面设置virtual tokens,等待优化。

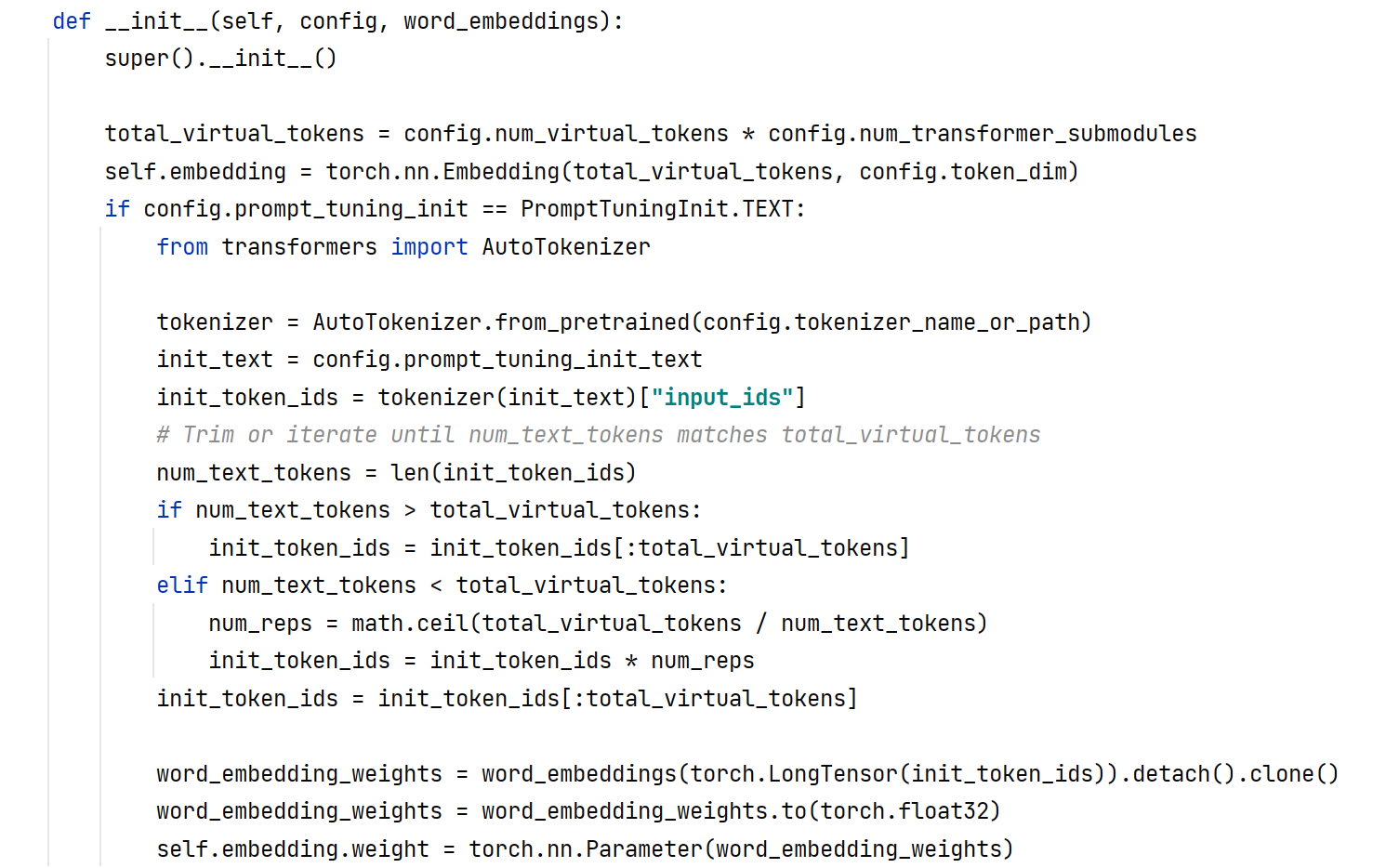
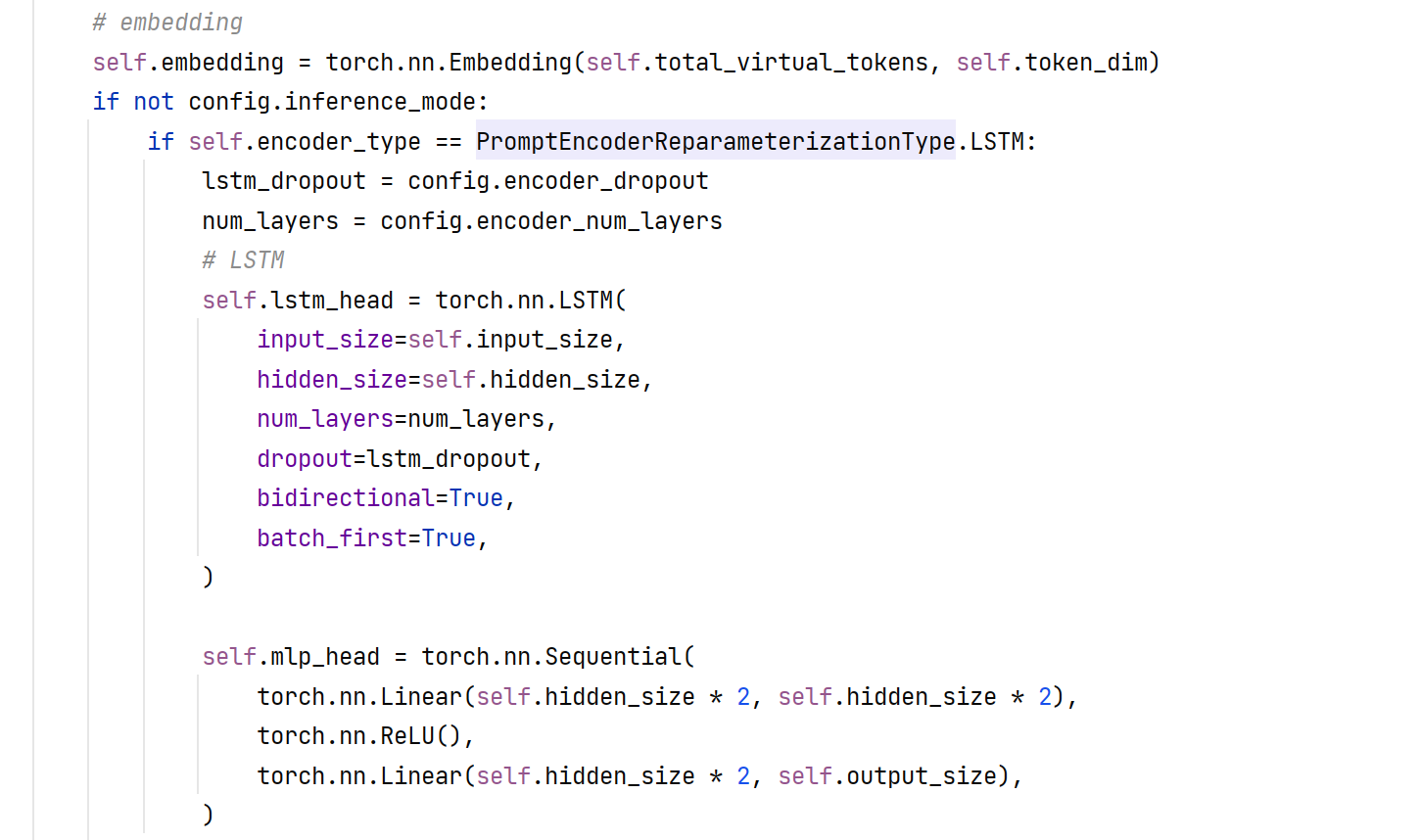
2.2 P-Tuning
在输入层的Prompt的任意位置设置virtual tokens,等待优化,同时使用LSTM+MLP重参数化Prompt

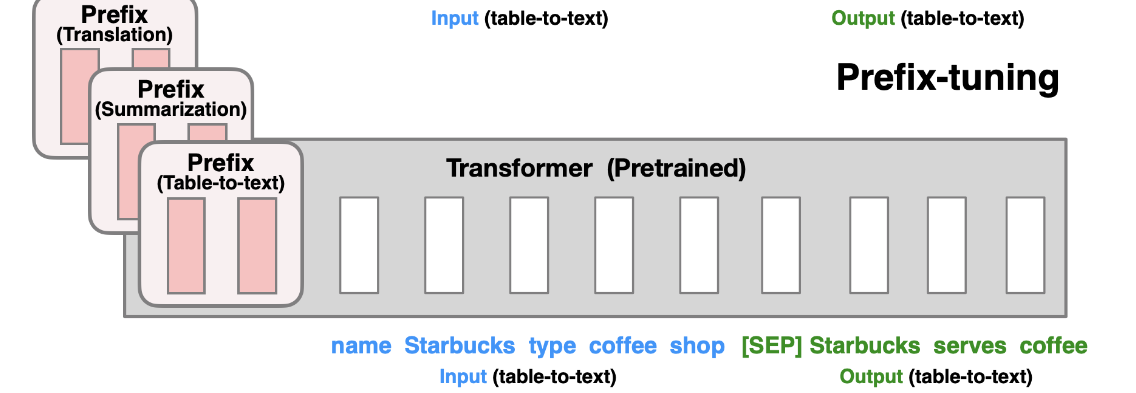
2.3 Prefixt-Tuning
在每一层的layer的Prompt的前面设置virtual tokens,等待优化,同时使用两层MLP去编码prefix prompt。
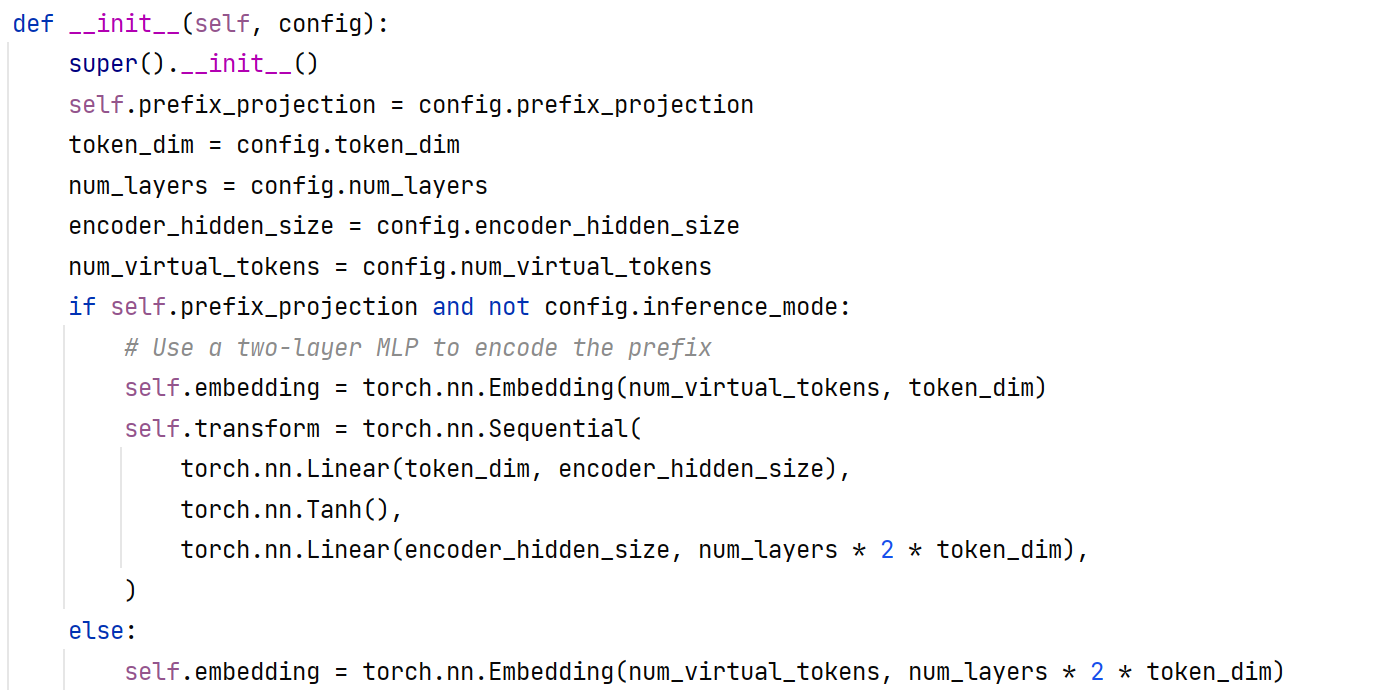
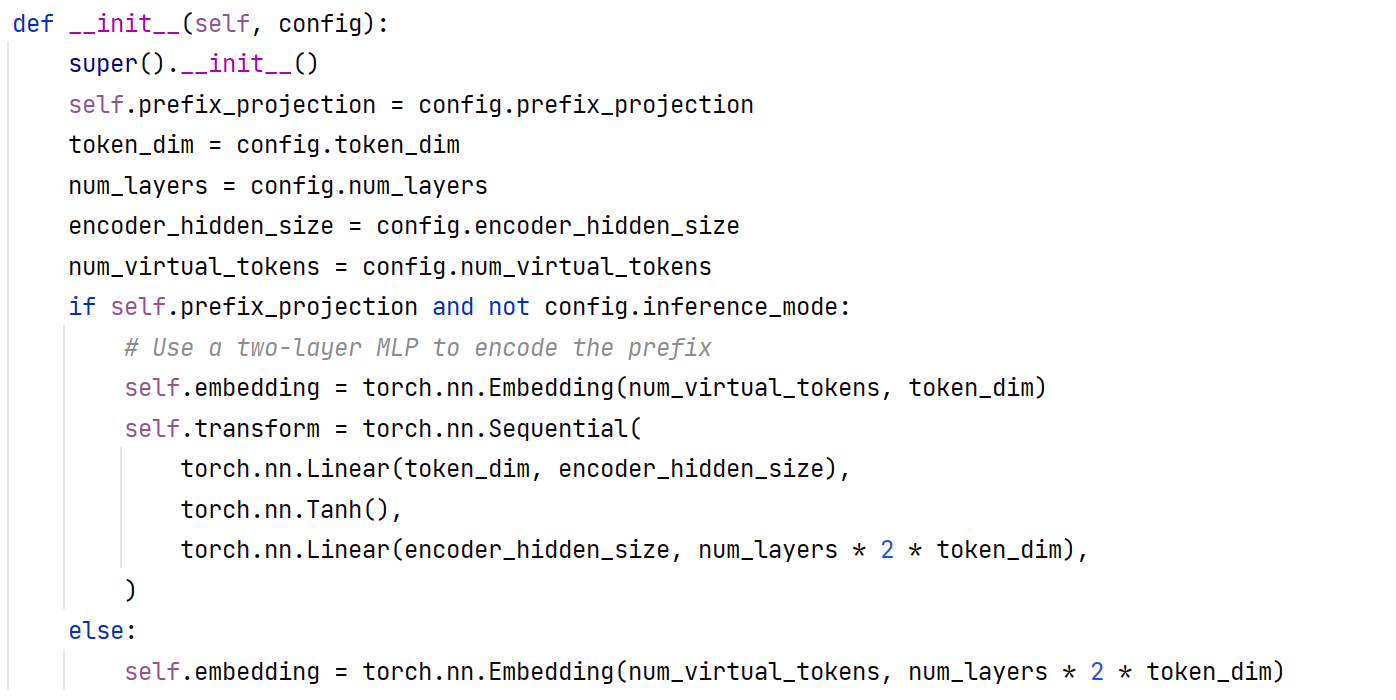
2.4 P-TuningV2
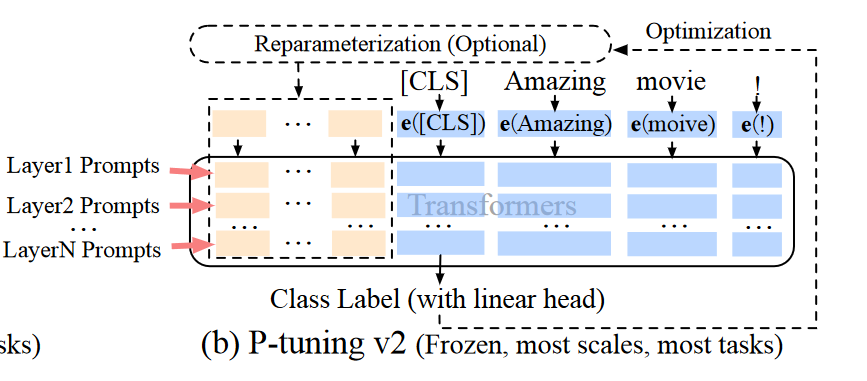
在每一层的layer的Prompt的前面设置virtual tokens,等待优化,同时不做重参数化。
3 参考文献
3.1 Blogs
DoRA: [LoRA再升级!英伟达 | 提出权重分解低阶适应:DoRA,极大的增强模型学习能力 (qq.com)](https://mp.weixin.qq.com/s/PYFfcvD3bMmc1m6zcYH2SA)
LISA: [港大 | 提出高效大模型微调方法:LISA,性能碾压LoRA,甚至可超全参数微调! (qq.com)](https://mp.weixin.qq.com/s/Y_Xbpaat3ClZ6LIUkUzg9A)
LISA: [一张3090性能超越全参调优!比LoRA还快50%的微调方法来了 (qq.com)](https://mp.weixin.qq.com/s/tTjzWsEtM2hpteHUBMkL-Q)
LoRAMoE: [一周前被MoE刷屏?来看看LoRAMoE吧!通过类MoE架构来缓解大模型世界知识遗忘 (qq.com)](https://mp.weixin.qq.com/s/IrucM2GIXkjYamssG1-dxg)
VeRA: [VeRA: 性能相当,但参数却比LoRA少10倍 (qq.com)](https://mp.weixin.qq.com/s/XqX1qxDMy3rX7XC-_frkIg)
MTLoRA: [震惊,LORA被碾压了?多任务学习新突破!MTLoRA实现3.6倍参数高效适配,精度超越全微调 (qq.com)](https://mp.weixin.qq.com/s/3l2Px7UG98l5rbaptdw4Nw)
LongLoRA: [ICLR 2024 || LongLoRA:长文本的大模型微调 (qq.com)](https://mp.weixin.qq.com/s/CAw5GdpsAN6IhlxYPInNCQ)
LoRA合集: [LoRA及其变体概述:LoRA, DoRA, AdaLoRA, Delta-LoRA (qq.com)](https://mp.weixin.qq.com/s/-_JqRklaRI9bD_6QQGKrjg)
NeFT: [澳门大学 | 提出神经元级高效微调方法:NeFT,秒杀LoRA,性能超全参微调(FPFT)! (qq.com)](
3.2 Papers
LoRA: [[2106.09685\] LoRA: Low-Rank Adaptation of Large Language Models (arxiv.org)](https://arxiv.org/abs/2106.09685)
AdaLoRA:[[2303.10512\] AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning (arxiv.org)](https://arxiv.org/abs/2303.10512)
QLoRA:[[2305.14314\] QLoRA: Efficient Finetuning of Quantized LLMs (arxiv.org)](https://arxiv.org/abs/2305.14314)
Dora:[[2402.09353\] DoRA: Weight-Decomposed Low-Rank Adaptation (arxiv.org)](https://arxiv.org/abs/2402.09353)
LISA:[[2403.17919\] LISA: Layerwise Importance Sampling for Memory-Efficient Large Language Model Fine-Tuning (arxiv.org)](https://arxiv.org/abs/2403.17919)
NeFT:[[2403.11621v1\] Let’s Focus on Neuron: Neuron-Level Supervised Fine-tuning for Large Language Model (arxiv.org)](https://arxiv.org/abs/2403.11621v1)
LoRAMoE:[[2312.09979\] LoRAMoE: Alleviate World Knowledge Forgetting in Large Language Models via MoE-Style Plugin (arxiv.org)](https://arxiv.org/abs/2312.09979)
VeRA:[[2310.11454\] VeRA: Vector-based Random Matrix Adaptation (arxiv.org)](https://arxiv.org/abs/2310.11454)
MTLoRA:[[2403.20320\] MTLoRA: A Low-Rank Adaptation Approach for Efficient Multi-Task Learning (arxiv.org)](https://arxiv.org/abs/2403.20320)
LongLoRA:[[2309.12307\] LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models (arxiv.org)](https://arxiv.org/abs/2309.12307)
LoRA+:[[2402.12354\] LoRA+: Efficient Low Rank Adaptation of Large Models (arxiv.org)](https://arxiv.org/abs/2402.12354)
LoRA – FA:[[2308.03303\] LoRA-FA: Memory-efficient Low-rank Adaptation for Large Language Models Fine-tuning (arxiv.org)](https://arxiv.org/abs/2308.03303)
LoRA – Drop:[[2402.07721\] LoRA-drop: Efficient LoRA Parameter Pruning based on Output Evaluation (arxiv.org)](https://arxiv.org/abs/2402.07721)
Delta – LoRA:[[2309.02411\] Delta-LoRA: Fine-Tuning High-Rank Parameters with the Delta of Low-Rank Matrices (arxiv.org)](