1 面试题预告
- 1 手写一个multi-head attention?
- 2 LoRA的细节?
- 3 left-padding和right-padding的区别?
- 4 transformer中为什么计算注意力需要除以根号dk?
- 5 MQA和GQA的具体实现?
- 6 KV Cache?
- 7 手写LayerNorm和RMSNorm?
- 8 Batchnorm和LayerNorm的区别?
- 9 Pre-Norm和Post-Norm的区别?
2 面试题答案
2.1 手写一个multi-head attention?
import torch.nn as nn
import torch
import torch.nn.functional as F
class SelfAttention(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_heads):
super().__init__()
self.num_heads = num_heads
self.head_hidden = hidden_size // num_heads
self.Wq = nn.Linear(input_size, hidden_size)
self.Wk = nn.Linear(input_size, hidden_size)
self.Wv = nn.Linear(input_size, hidden_size)
self.Wo = nn.Linear(hidden_size, output_size)
def forward(self, x):
# x -> (batch_size, seq_len, hidden_size)
batch_size, seq_len, hidden_size = x.shape
xq = self.Wq(x).view(batch_size, seq_len, self.num_heads, -1)
xk = self.Wq(x).view(batch_size, seq_len, self.num_heads, -1)
xv = self.Wq(x).view(batch_size, seq_len, self.num_heads, -1)
# xq -> (batch_size, seq_len, head_nums, hidden) -> (batch_size, head_nums, seq_len, hidden)
xq, xk, xv = xq.transpose(1, 2), xk.transpose(1, 2), xv.transpose(1, 2)
# attention -> (batch_size, head_nums, seq_len, seq_len)
attention = xq @ xk.transpose(2, 3) / torch.sqrt(torch.tensor(xq.shape[-1]))
scores = F.softmax(attention, dim=-1)
# value -> (batch_size, head_nums, seq_len, hidden)
output = scores @ xv
# value -> (batch_size, seq_len, head_nums, hidden) -> (batch_size, seq_len, hidden_size)
output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, -1)
output = self.Wo(output)
return output
input_size = 100
hidden_size = 100
output_size = 100
num_heads = 5
x = torch.randn(size=(32, 10, 100))
self_attention = SelfAttention(input_size, hidden_size, output_size, num_heads)
output = self_attention(x)
print(output.shape)2.2 LoRA的细节?
delta W = B @ A * scaling
x -> (batch_size, input_size) A -> (input_size, r) B -> (r, output_size)
result = self.B(self.A(x)) * self.scaling -> (batch_size, output_size)
为什么需要Scaling?
- 1 scaling中除以r是为了对输出取均值
- 2 scaling中乘以lora_alpha是为了作为超参进行性能调整
A,B矩阵的初始化?
- 1 B矩阵初始化为0矩阵
- 2 A矩阵使用高斯随机初始化
2.3 left-padding和right-padding的区别?
预训练过程:预训练过程中一般不使用padding。
推理过程:
- right-padding会导致input和output之间夹杂padding,不利于语义连续以及处理输出结果。
- 由于huggingface的casual llm的类的实现方法是使用最后一个token预测下一个token,如果设置padding size = right, 故此时padding token参与了下一个token的预测,由于预训练没有该种训练,故预测结果有误。
事实上如果改写推理类,使用padding token前一个token进行next token的预测也可以实现,只是推理类需要实时记录每一个序列的长度。综合下来不如使用left_padding。
2.4 transformer中为什么计算注意力需要除以根号dk?
归一化;
q@k中假设q和k服从标准正态分布的随机变量,均值为0,方差为dk。故是为了进行归一化,防止数据溢出,同时保证梯度的平稳。
2.5 MQA和GQA的具体实现?

自回归模型生成回答时,需要前面生成的KV缓存起来,来加速计算。多头注意力机制(MHA)需要的缓存量很大,Multi-Query Attention指出多个头之间可以共享KV对。Group Query Attention没有像MQA一样极端,将query分组,组内共享KV.
2.6 KV Cache?
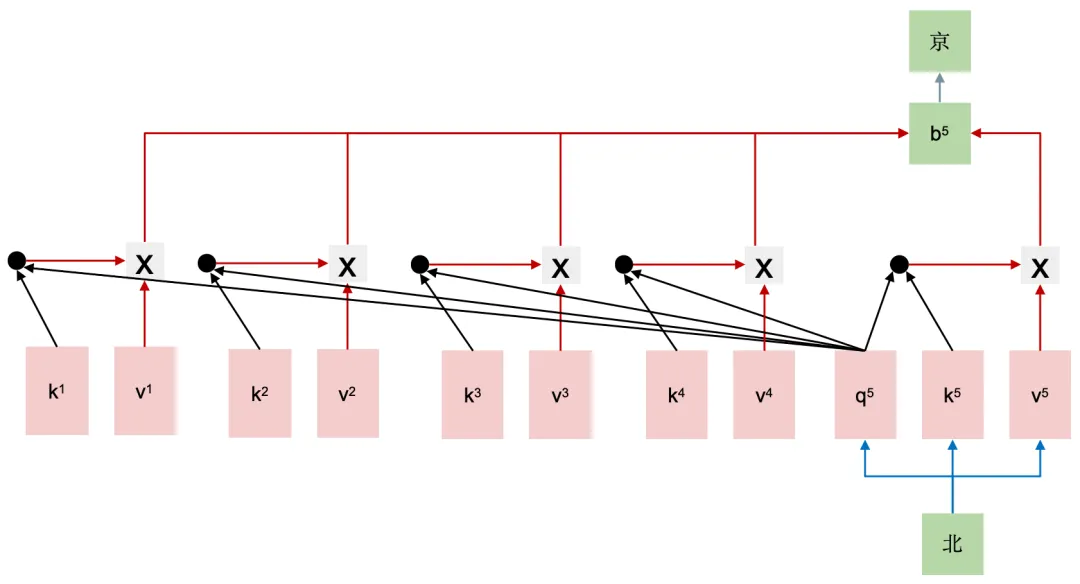
存储前面seq_len的k和v数据。
2.7 手写LayerNorm和RMSNorm?
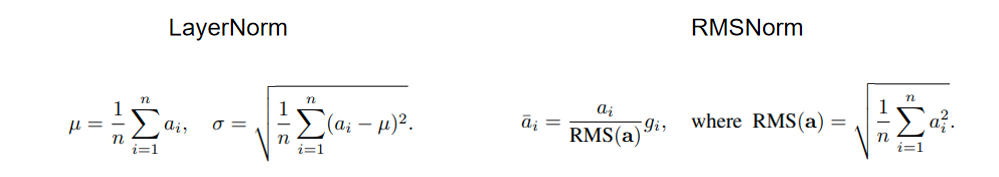
layernorm:
class LayerNorm(nn.Module):
def __init__(self, d_dim, bias):
super(LayerNorm, self).__init__()
self.weight = nn.Parameter(torch.ones(d_dim), requires_grad=True)
if bias:
self.bias = nn.Parameter(torch.zeros(d_dim), requires_grad=True)
else:
self.bias = torch.zeros(d_dim)
self.eps = 1e-8
def _norm(self, x):
mean = x.mean(-1, keep_dim=True)
std = x.std(-1, keep_dim=True)
return (x - mean) / (std + self.eps)
def forward(self, x):
return self.weight * self._norm(x) + self.biasrmsnorm:
class RMSNorm(nn.Module):
def __init__(self, d_dim, bias):
super(RMSNorm, self).__init__()
self.weight = nn.Parameter(torch.ones(d_dim), requires_grad=True)
if bias:
self.bias = nn.Parameter(torch.zeros(d_dim), requires_grad=True)
else:
self.bias = torch.zeros(d_dim)
def _norm(self, x):
return x * torch.rsqrt(x.pow(2).mean(-1, keep_dim=True))
def forward(self, x):
return self.weight * self._norm(x) + self.bias2.8 Batchnorm和LayerNorm的区别?
2.8.1 归一化
- 1 加速收敛和稳定训练过程:归一化可以使得数据分布更加均匀,减少梯度消失或爆炸的问题,从而加速神经网络的收敛速度。通过将数据缩放到一个较小的范围(例如,均值为0,方差为1),网络参数的更新更加平稳,学习率可以设置得更大,进而加快训练进程。
- 2 增加泛化性:归一化有助于减少模型对输入数据微小变化的敏感性,使得模型更加鲁棒。这有助于提高模型的泛化能力,即在未见过的数据上表现更好。
- 3 简化超参数选择:归一化可以减少对学习率等超参数的敏感性,使得这些参数的选择更加容易。在未归一化的数据上,可能需要精细调整学习率以避免训练过程中的不稳定,而归一化后,可以使用更大的学习率,简化了超参数的选择过程。
- 4 增强模型解释性:归一化后的数据通常具有更加一致的尺度,这有助于更好地理解和解释模型的输出。例如,在特征归一化后,模型输出的变化可以更容易地与输入特征的变化相关联。
2.8.2 BatchNorm
基础理论:
假设输入x的形状为[B, C],则batchnorm会对batch维度 B计算均值和方差进行归一化计算,同时对归一化之后的参数进行超参数缩放系数y和偏移系数b的学习,初始情况下y为1,b为0。
针对CNN,输入x的形状为[B, C, H, W],则特征值个数为C,BatchNorm需要对B*H*W个向量计算均值和方差。
训练和推理:
- 1 训练过程中学习缩放系数y和偏移系数b,推理时直接使用,但是推理过程中却不方便计算均值和方差;
- 2 训练过程使用移动平均来使用batch的均值和方差来近似全局的均值和方差;
- 3 如果batch_size太小,则近似的误差会很大;
2.8.3 LayerNorm
基础理论:
时序模型的输入为[B, S, H],由于输入序列不等长,使用padding将其补全为S维度,故不使用BatchNorm(padding的存在影响了batchnorm的计算过程)。
相比BatchNorm在batch维度[B, S, ]做归一化,LayerNorm集中在对feature维度[, H]做归一化。
训练和推理:
LayerNorm在训练和推理过程都统一计算。
2.9 Pre-Norm和Post-Norm的区别?
pre-norm和post-norm:
post-norm是在残差和主干相加之后进行归一化,pre-norm则是在主干先归一化再和残差相加。
post-norm和pre-norm对比,目前大家比较接受的结论是,pre-norm更容易训练,因此可以叠加更多的层,但是在层数不是特别多的情况下,post-norm最终的收敛效果会比pre-norm要好。
warmup:
- 1 post-norm的transformer,在初始化时候,靠近输出层的部分梯度期望很大,所以模型在开始训练的时候很依赖warmup的策略,通过缓慢提升学习率来稳定训练过程。
- 2 pre-norm的transformer在不需要warmup的情况下,也能收敛到post-norm+warmup的相同水平,而post-norm不加warmup效果就差点了。