论文名称:LongWriter: Unleashing10,000+ Word Generation from Long Context LLMs
论文地址:https://arxiv.org/abs/2408.07055
代码:https://github.com/THUDM/LongWriter
大模型的上下文输入长度已经到了100k级别,但是基本上却不乏做到输出2k+ tokens。主要原因来自SFT过程,SFT过程的output中大部分都是short response,这导致模型最终无法生成超长文本。
作者贡献:
- 1 开发了AgentWrite生成超长文本;
- 2 构建了LongWriter-6k超长文本生成数据集;
- 3 构建了LongBench-Write benchmark长文本生成评估数据集;
- 4 构建了超长文本生成SFT和DPO数据集;
- 5 训练了LongWriter模型;
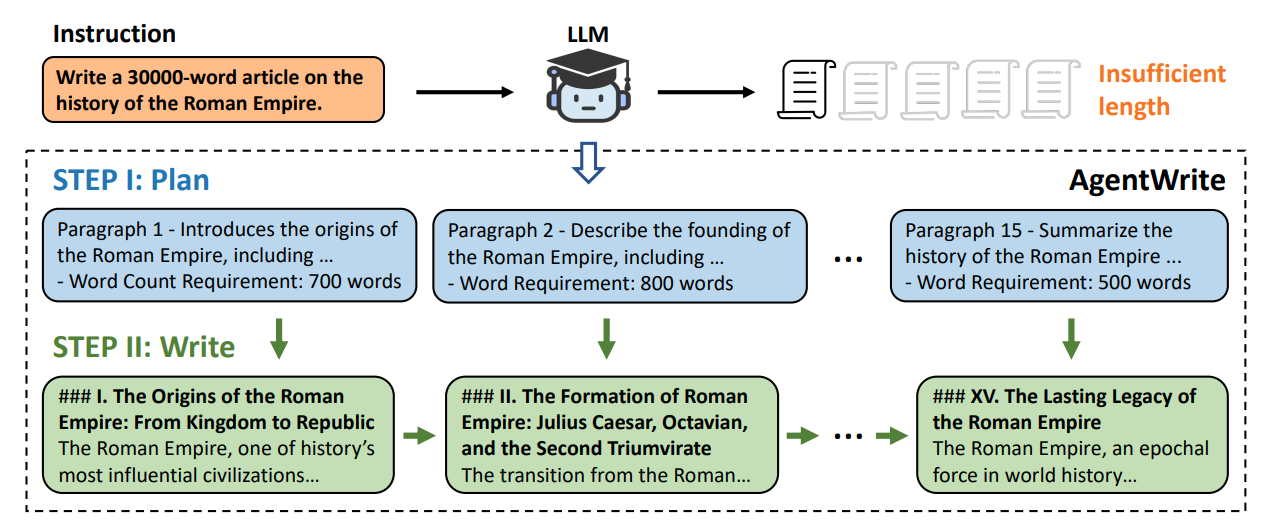
1 AgentWrite
为了得到长文本输出,作者使用AgentWrite方法,通过将instruction分解为多个子问题,让大模型根据instruction 和n-1 section已生成的内容来生成n section内容。
AgentWrite共使用了6k的instruction:
- 1 GLM-4 的 SFT 数据中筛选出了 3,000 条指令
- 2 WildChat-1M中选择了3,000条指令(主要是英文)
最终通过AgentWrite得到LongWriter-6k数据集。
2 LongBench-Write
LongWriter 还开发了 LongBench-Write,这是一个用于评估超长生成能力的综合基准。
3 LongWriter
3.1 SFT数据构建
SFT数据集:LongWriter-6k+GLM4’s SFT-180k;
3.2 DPO数据构建
DPO数据集:GLM-4’s chat DPO data – 50k;
3.3 LongWriter
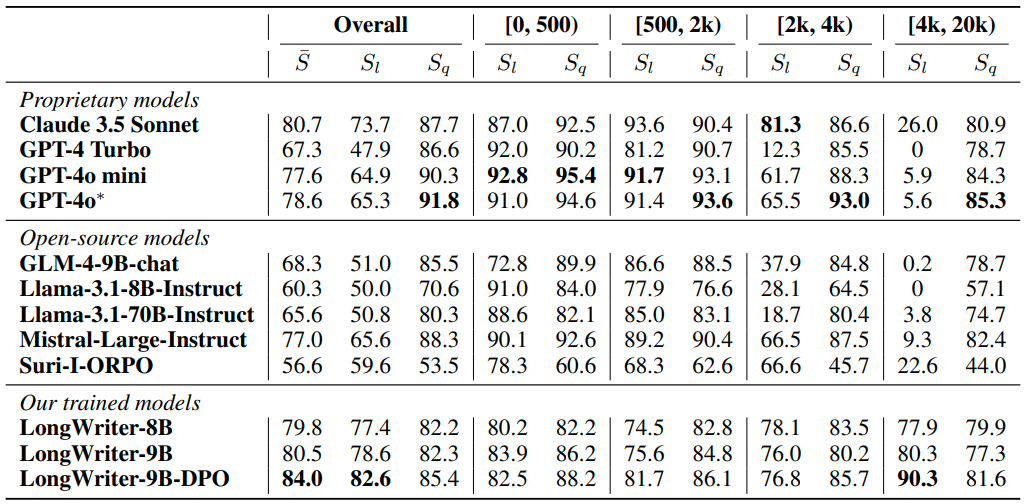
GPT-4o为打分模型;Sl为输出长文本的长度打分;Sq为输出长文本的质量打分;