论文名称:Black-Box Prompt Optimization: Aligning Large Language Models without Model Training
论文代码:https://github.com/thu-coai/BPO
1 背景和贡献
背景:在对齐工作中,为了让大模型能理解用户的意图,大家的关注点往往在模型针对用户提问的回复上,而本论文的关注点在于用户提问上,即能否缩小用户提问和大模型能理解的提问之间的gap。
贡献:本文提出了BPO,通过small llm改写用户的提问,使其更适合大模型理解,其效果甚至超过了DPO和PPO。
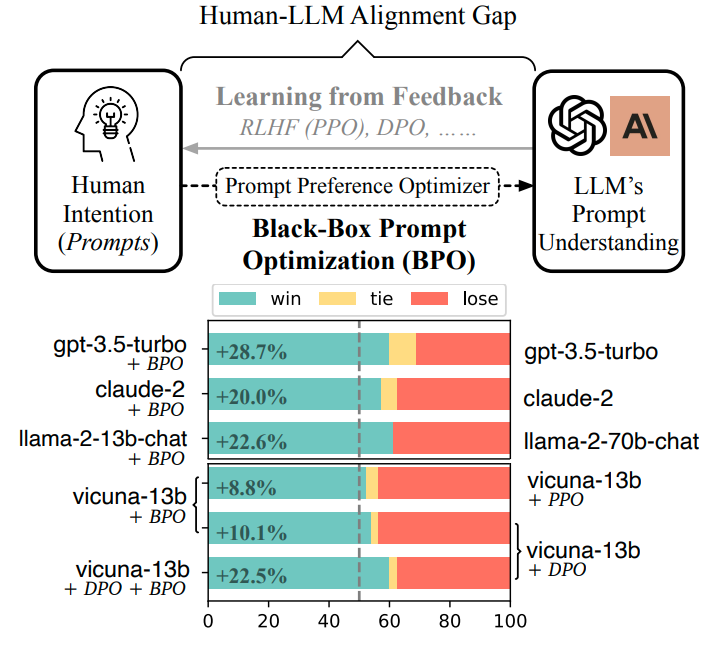
2 BPO
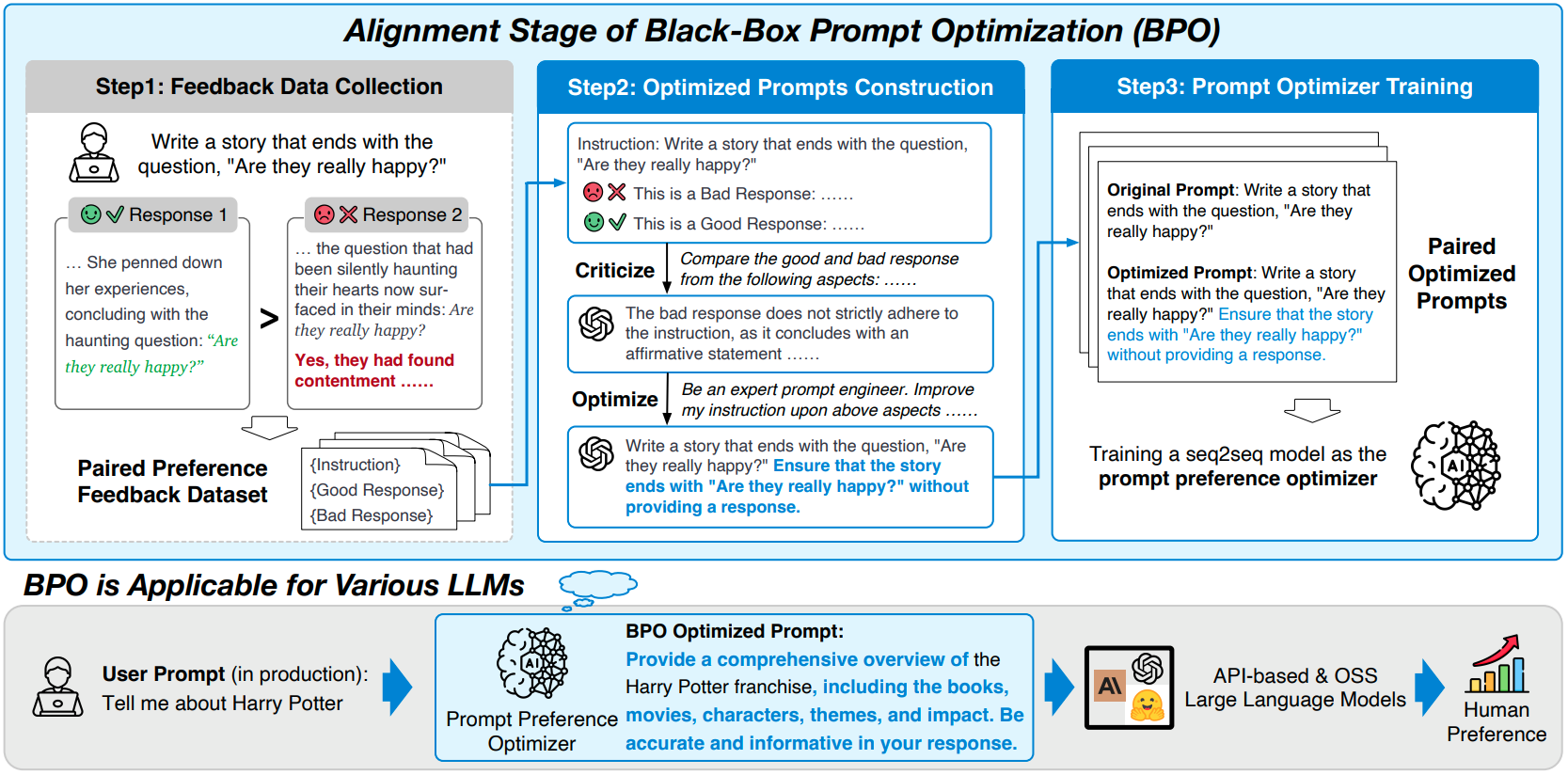
2.1 训练数据集构造
我们定义用户输入为X_uesr,Y_good为良好回复,Y_bad为不好回复,将(X_user, Y_good, Y_bad)输入给ChatGPT生成X_opt(优化后的instruct)。
2.2 训练优化
输入为:(X_user, Y_good, Y_bad)
输出为:X_opt
优化模型:Llama2-7B
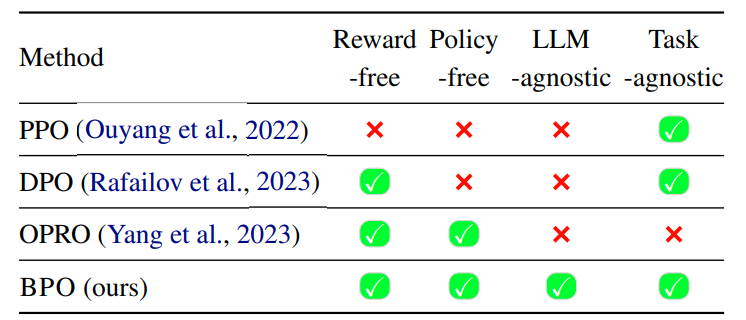
2.3 BPO的优势
BPO is free from training reward or policy models, andagnostic to any LLMs or tasks in application.
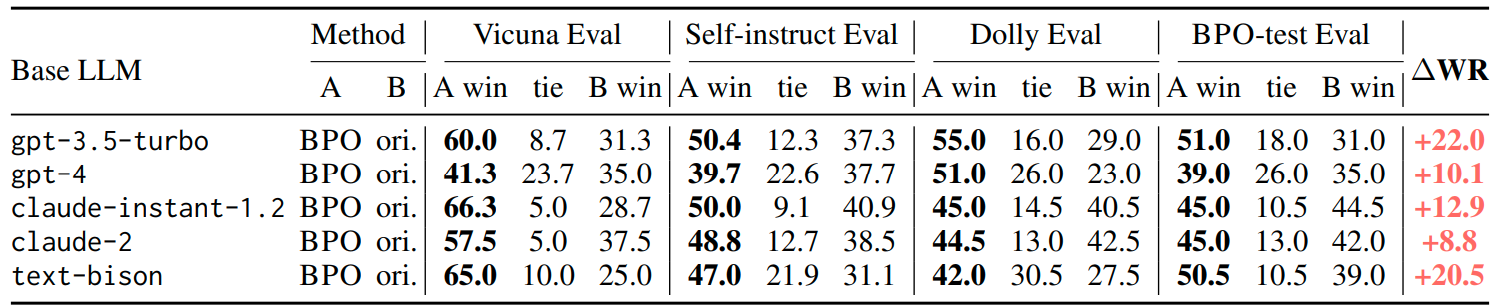
2.4 Experiment