论文名称:LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
论文地址:https://arxiv.org/pdf/2308.14508
论文代码:https://github.com/THUDM/LongBench
1 背景/贡献
目前大模型的上下文窗口越来越大,从4k->8k->32k->128k->256k->1M,但是没有足够的benchmark来测量long-context的能力。
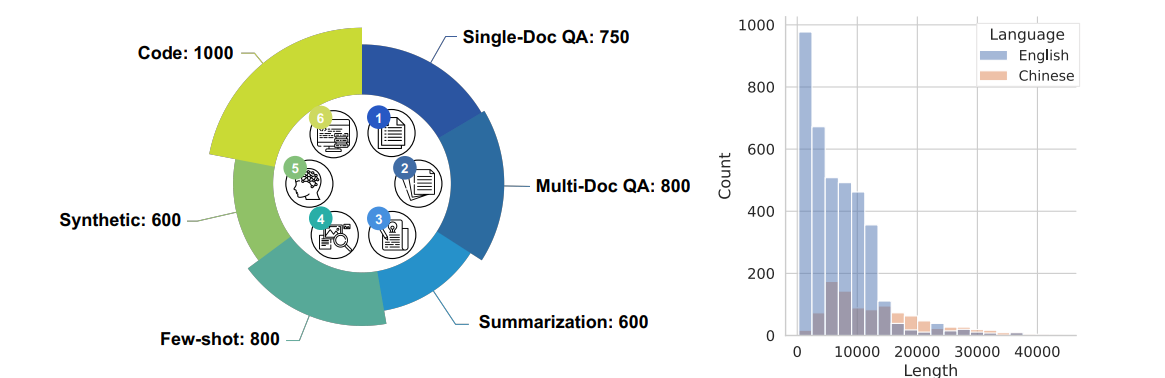
本文提出了LongBench,这是一个双语的包含6个任务,21个数据集的benchmark,其中英文样本的平均长度为6711,中文的平均长度为13386。
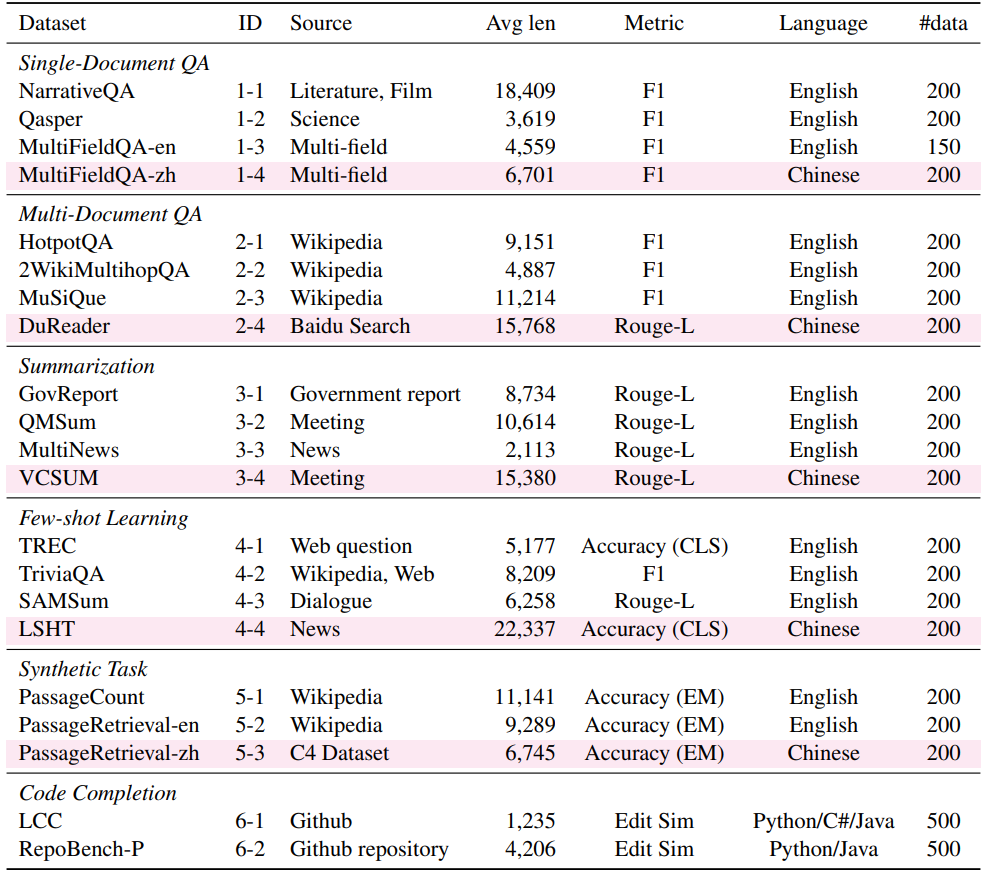
六大任务如下: single-doc QA; multi-doc QA; summarization; few-shot learning; synthetic tasks; code completion.
为了去除task对长上下文测评的影响,与LongBench的随机取样不同,LongBench-E针对长文本长度区间均匀采样构成数据集来揭示不同大模型处理长上下文的能力。
2 Data Collection
2.1 single-doc QA
single-doc来自原始文本,需要确认question-answer pair匹配。
2.2 multi-doc QA
answer来自multi-doc中,需要确认question-answer pair匹配。
2.3 summarization
QA问题可能更需要局部信息,而总结问题更需要long-context的全局信息。
2.4 few-shot learning
For TREC, LSHT, SAMSum, and TriviaQA, the few shot ranges are [100, 600], [10, 40], [10, 100], [2, 24]
2.5 synthetic tasks
该合成任务主要分为两类:
- 1 PassageRetrieval:给定30个passages,使用gpt3.5写其中1个passage的summarization,task描述为让大模型指出该summarization来自哪个passage。
- 2 PassageCount:随机选择几个passages,同时对这几个passages随机进行不同数量的重复,task描述为让大模型指出有几个唯一段落?。
2.6 code completion
代码补全任务
3 Data Extraction
4 Experiment